

本书 《网络协议栈入门》 采用的代码是 基于 linux 内核 4.4.4 版本的。linux 内核源码下载地址: mirrors.edge.kernel.org
我自己做了多年的PHP 开发,序列化函数 serialize() 也经常用,我只是知道把一个 php 变量存储进去文件,需要先序列化,就能存了。
但是我一直没去了解 序列化的原理。
最近在看协议实现,C 语言是可以直接把 一个 int num = 0x11223344 的变量,直接从内存写到 文件 a.txt 存储。int 占 4个字节,如果是本机读取,大小端一致,就可以读 文件 a.txt 4个字节,然后内存拷贝给 int num 使用。代码如下:
//write.c 写入数据文件。
#include <stdio.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
int fd = open("a.txt",O_RDWR|O_CREAT);
if( -1 == fd ){
perror("Error:"),exit(-1);
}
printf("打开文件成功 fd = %d \r\n",fd);
int age = 0x11223344;
int write_num = write(fd,&age,sizeof(int));
return 0;
}上面的代码可以用 qt creator + mingw32 运行,或者在 linux 下用 gcc 编译,编译命令如下:
# 生成 .o 文件
gcc -c write.c
# 把 .o 文件链接 成 可执行文件,这里只有一个 .o
gcc -o write write.o运行上面的 write 程序之后,会生成 a.txt,我们用 notepad++ 32位 的16进制插件打开 a.txt 查看他的内容,如下:
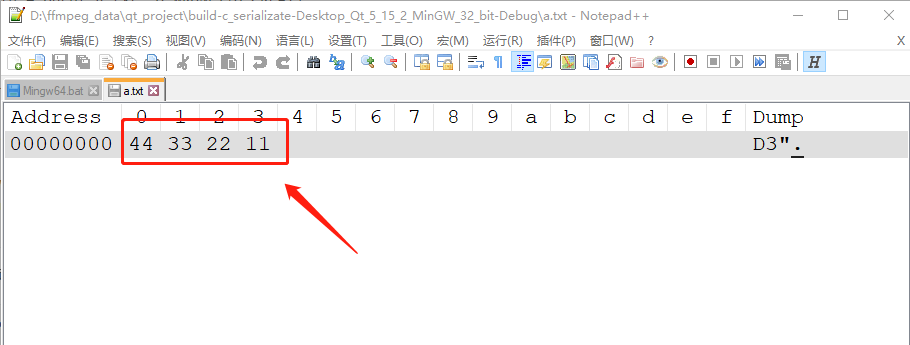
可以看到,数据是逆向排列的,所以我的电脑 是小端序,字节序相关知识请看《网络通信中的字节序》。
这样,就成功把一个 变量存储 进去文件里面了。那是不是用另一个程序就能把这个 文件的内容拿出来?
是的,代码如下:
//read.c 读取数据文件。
#include <stdio.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
int fd = open("a.txt",O_RDONLY);
if( -1 == fd ){
perror("Error:"),exit(-1);
}
printf("打开文件成功 fd = %d \r\n",fd);
int age = 0;
printf("age 初始值是 0x%x \r\n",age);
int read_num = read(fd,&age,sizeof(int));
printf("读取数据 %d 字节, age 等于 0x%x \r\n",read_num,age);
return 0;
}read 程序的运行结果如下:
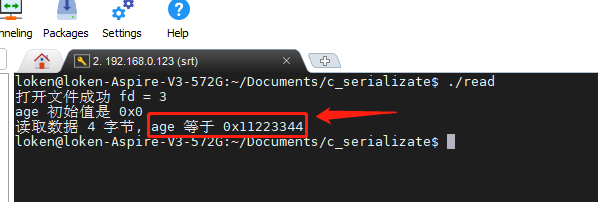
可以看到,是可以正常读取的,没有问题,但是由于不同的电脑设备有大小端区别,不同的编译器在处理一些复杂结构,例如 struct 的时候,内存对齐等原因的影响,导致上面的存储的方式跨平台不行。C语言结构体内存对齐知识请看《C语言内存对齐详解 》
上面这样存,如果把 a.txt 拿到大端的机器就解析错误了。因为大端序机器的 解析 是跟小端相反的。
所以为了解决 大小端字节序,不同编译器的差异,内存对齐 等问题,就需要用到 序列化技术,本文就来研究一下 序列化的 原理,为什么用了序列化就能解决大小端问题,一个简单的 int 序列化 如何用 C 语言实现,这些都是本文的重点。
序列化 技术 其实是一种与编程语言关联比较 深的技术,
例如 php 的 serialize() 把 $a = 0x11223344 序列化之后,变成字符串,i:287454020; ,但这种格式语法是 PHP 自己的。
JavaScript 用的是 JSON.parse() ,php 也有一个 json_encode() 函数,所以 PHP 跟 JavaScript 可以用 json 格式来交换数据通信。
所以 json 的跨语言特性比较好。相应的,还有 xml 也是序列化的一种语法,还有 JDK(不支持跨语言),Hessian,Kryo(不支持跨语言),Thrift,Protobuf,FST。
跨语言的原理,我自己也不太清楚,这个应该是程序语言设计的领域知识。
所以,可以看出来,序列化 实际上 就是一种 描述 数据类型的 存储方式的 一种语法。每种编程语言都有自己的特定的数据类型,所以 如果某种 序列化的语法 可以解析 成 PHP 的对象,也可以解析 成 JAVA 的对象,那这种 序列化 的语法 就是 跨语言的。
跨语言的序列化 实现太复杂,本文主要实现一个 C语言的 序列化语法。
就拿 php 的 的 serialize() 来举例演示。php 是C 语言写的,所以C 语言也能实现一个 serialize(),如下:
#include <stdio.h>
#include <fcntl.h>
#include <stdlib.h>
char* serialize(int num){
char str[] = "i:287454020;";
int len = strlen(str)+1;
char* str2 = malloc(len);
memcpy(str2,str,len);
return str2;
}
int main()
{
int fd = open("a.txt",O_RDWR|O_CREAT);
if( -1 == fd ){
perror("Error:"),exit(-1);
}
printf("打开文件成功 fd = %d \r\n",fd);
int num = 0x11223344;
char* str = serialize(num);
int write_num = write(fd,str,strlen(str));
close(fd);
return 0;
}上面的 serialize() 我是用伪代码实现的,返回一个字符串。然后写进去文件里面。打开 a.txt 查看内容,如下:
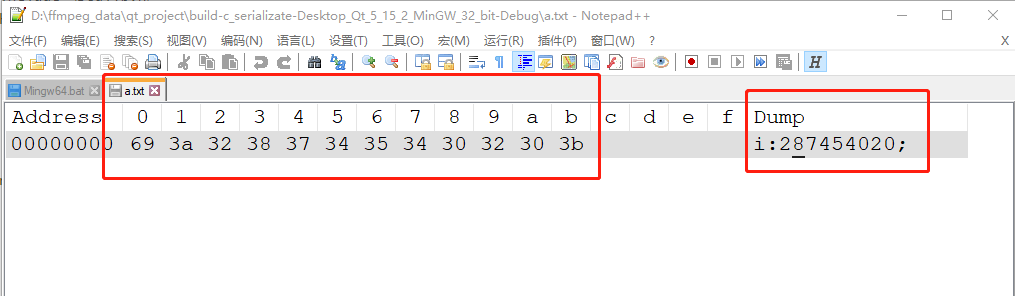
可以看到,存储的内容是 ASCII码 ,也就是存储的是 字符串对应的 二进制 ASCII码,这种方式 叫字符串存储,虽然最后写到硬盘还是二进制 的 ASCII码。
那为什么用字符串 存储就能解决大小端问题?接下来 就是精髓。
什么是大小端问题?多字节的数据类型 在不同 设备的 内存数据排列顺序不一样,怎么解决?这里注意,只有多字节数据类型才有大小端问题。
如果,我只存 char 进去文件,char 是单字节,高位是他,低位也是他。就不存在什么大小端字节的问题。
字符串就是 char 存储的,一个一个char 连起来,所以 字符串是单字节存储,不存在高低位。
所以 字符串的存储方式,实际上 就是用 单字节数据类型 来描述 多字节数据类型。这个 描述 就是序列化的语法。
然后再看看 怎么解析 序列化的 语法,这个解析的过程 也叫 parse,代码如下:
C语言代码逻辑
1,把 文件i:287454020 读进来 char[] 数组,结束符 是";",所以遇到 ";" 就停止读取。
2, 对 字符串 进行 parse,读第一个字节,发现是 i ,那就说明后面的 字符串是一个 int 的数据类型。
3,创建 一个 int 变量, int num;
4, 调用 atoi 函数即可把字符串 “287454020”转成 int。
5,int num = atoi(“287454020”) 这样就完成一个 parse 了。所以,序列化技术 如果 是基于字符串实现的,那就是用 单字节 来描述 多字节数据。这样就能解决大小端问题。
PHP 的 serialize(),JSON,XML,这些 都是基于字符串实现的序列化,只需要对字符串进行 parse,就能还原回去之前的数据结构。
Google 的 Protobuf 序列化技术 不是 用字符串存储实现的,他这个东西我用过一下,序列化之后是二进制存储,不是字符串的ASII码的二进制。
具体 Protobuf 序列化技术 是如何实现的,请看《protobuf编码原理》
在UDP TCP 编程中,解决大小端问题 有两种做法。
1,规定 TCP body,UDP body 里面的各个数据字段,占多少字节,然后确定是大端还是小端排列。这个是设计一个新的协议的做法。
2,TCP 通常会有粘包问题,会设计一个4个字节的size,size规定是大端排序,然后 size 后面的数据序列化 之后再 传输。
然后对面的TCP先读 4个字节的size,把大端字节序转成主机字节序,拿到后面的数据长度之后,再循环读取数据,读够数据之后再反序列化。
序列化的方式比较容易扩展,加字段非常方便。
相关阅读:
由于笔者的水平有限, 加之编写的同时还要参与开发工作,文中难免会出现一些错误或者不准确的地方,恳请读者批评指正。如果读者有任何宝贵意见,可以加我微信 Loken1。QQ:2338195090。