

本书 《网络协议栈入门》 采用的代码是 基于 linux 内核 4.4.4 版本的。linux 内核源码下载地址: mirrors.edge.kernel.org
首先讲解一下什么是字节序,一般教科书会说:字节序是指数据在硬件中的排序方式。
上面这个答案,很全面,很正确,但是新人会看得云里雾里。
我用简洁的语言描述一下,做应用层开发的时候,经常遇到的情况是,一个数据类型,一个变量,在内存中的排列方式。
内存中的排列方式就是字节序,内存是其中一种硬件,还有CPU,GPU 也是硬件。
字节序有两种:
1,小端字节序,解析一个 int 是从内存 的 end 地址 往 start 地址,逆向回来解释的。
例如一个 变量 int num = 0x11223344 占 4个字节,内存地址是:0xcd9f37f7f0,所以 0xcd9f37f7f0 ~ 0xcd9f37f7f3 是 num 变量的内存。
那这个4 字节的内存存的是什么信息呢,0xcd9f37f7f0 是 0x44,0xcd9f37f7f1 是 0x33 ,0xcd9f37f7f2 是 0x22 ,0xcd9f37f7f3 是 0x11。
num 变量在内存里面是逆向存储的。CPU 读取 内存数据肯定是从 0xcd9f37f7f0 开始,从左往右读,但是解析的时候,CPU 知道 num 是一个 int,而且排列方式是逆向的,CPU 就会用逆向的方式解析这个 int。小端比较符合计算机的电路设计。
PS: 因为我们经常用的 memory 内存查看器,都是16进制的,所以上面我的 num 采样16进制赋值法。
2,大端字节序,解析一个 int 是从内存 的 start 地址 往 end地址,顺着解释的。符合人类的阅读习惯,从左往右看。
至于为什么要设计出大端小端,不统一用大端,推荐看这篇文章 《How to teach endian》。
那如何查看自己的电脑是 大端还是小端字节序。如图:
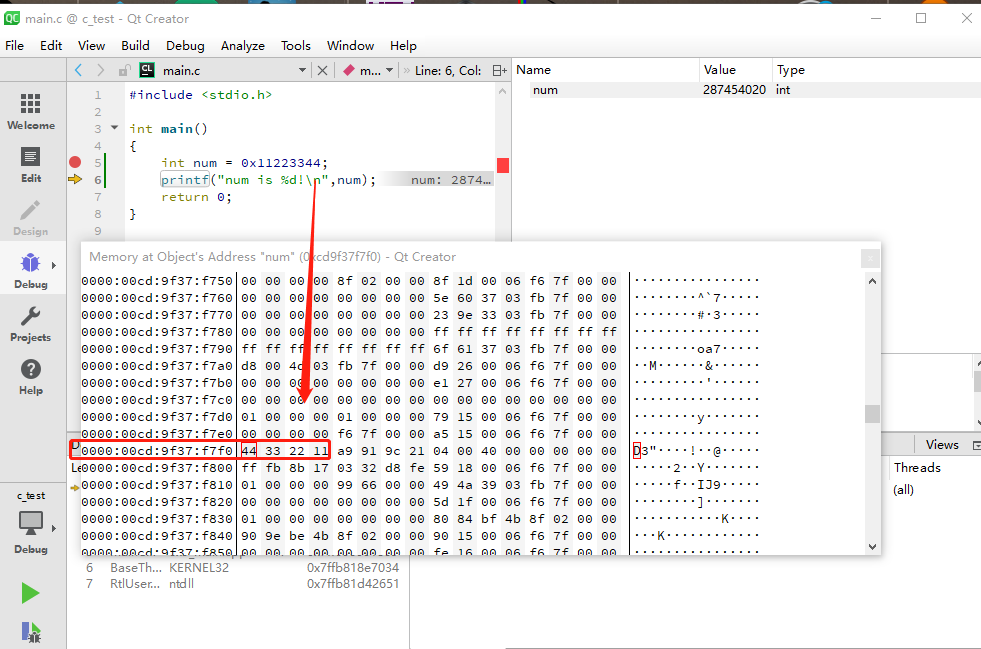
上图 ,我定义了一个 int num,int 占4个字节,0x 是16进制写法,所以 11 会占一个字节,22,占一个字节,类推。
从上图可以看出,num 在内存的存储 是逆向的,所以我的 window10 电脑是 小端字节序。
然后 再看 我另一台电脑 ubuntu系统的,如下:
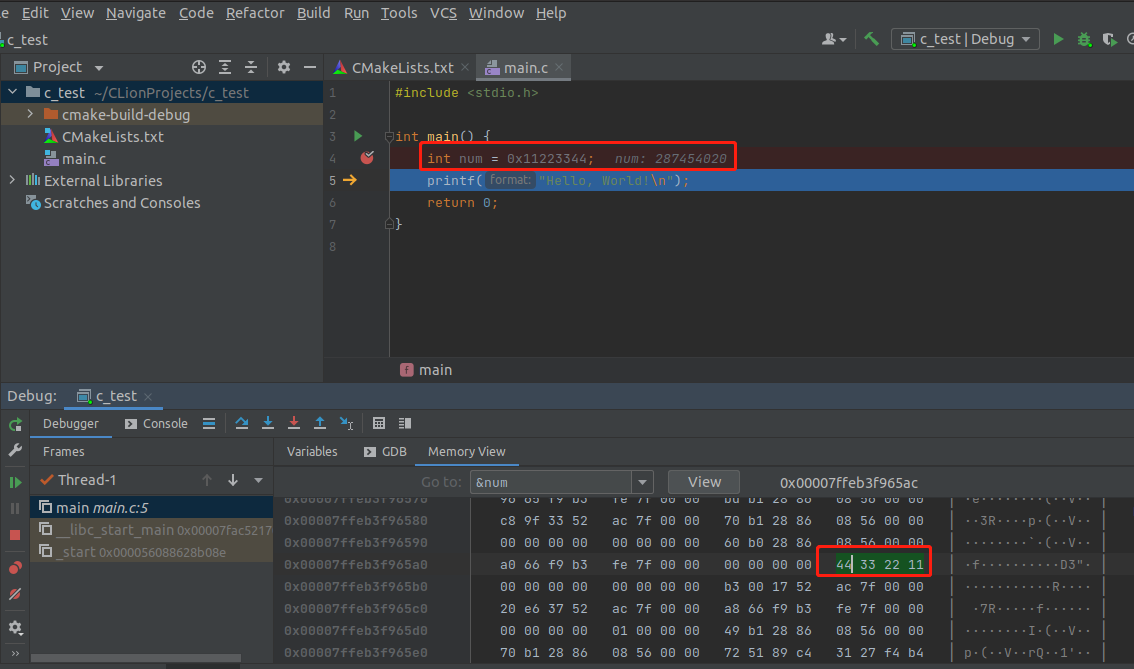
如上图,很遗憾,我的ubuntu也是小端字节,现在的网络环境,真不好找出一台大端字节序的机器给大家演示。
判断机器的字节序代码如下:
#include <stdio.h>
int main() {
int x = 0x1020304;
char* p = (char*)&x;
puts(p[0] == 1 ? "Big endian" : "Little endian");
return 0;
}基于以上背景,电脑设备分为 大端 小端字节序。所以在不同主机之间的 网络通信 中,规定使用哪种字节序就非常重要的。这个网络字节序就是大端字节序。
所以你通过 wireshark 可以看到 UDP header, TCP header,IP header,里面的字段都是大端排序的。如下:
servAddr.sin_addr.s_addr = inet_addr("192.168.0.123");
int port = 0x1122;
//注意这里
servAddr.sin_port = htons(port);上面的代码是 udp client 的部分代码,定义了 端口是 0x1122,因为我电脑是小端序,所以内存排列是 0x2211。但是经过 htons() 函数转换之后,内存排列就变成了 0x1122。
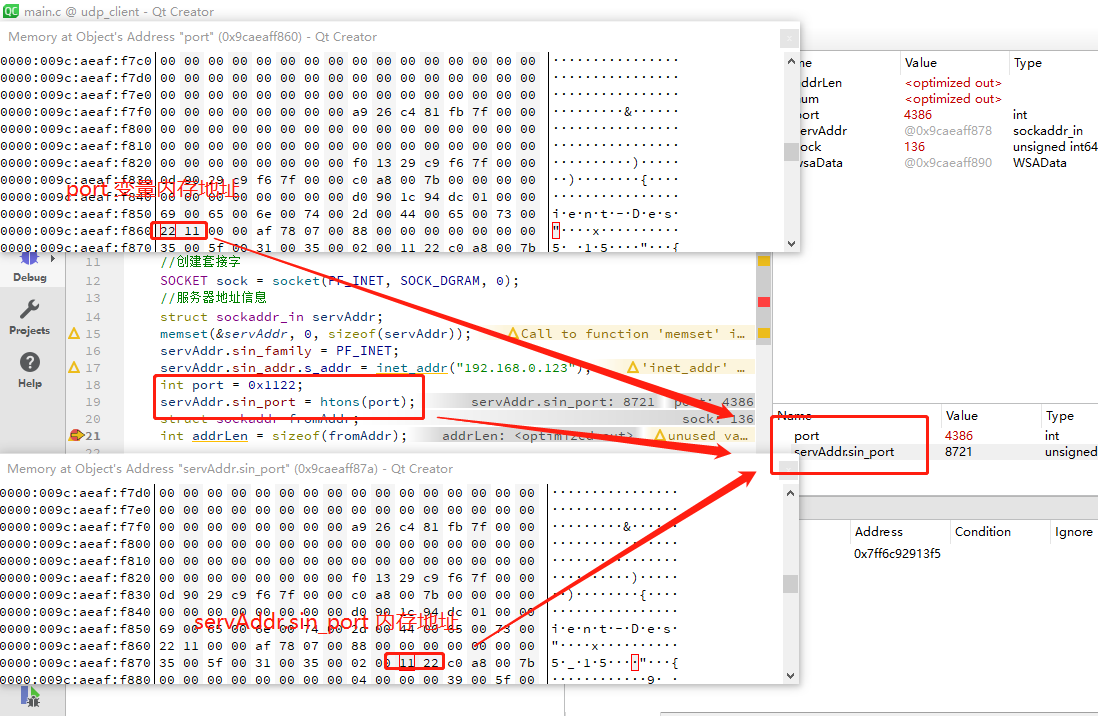
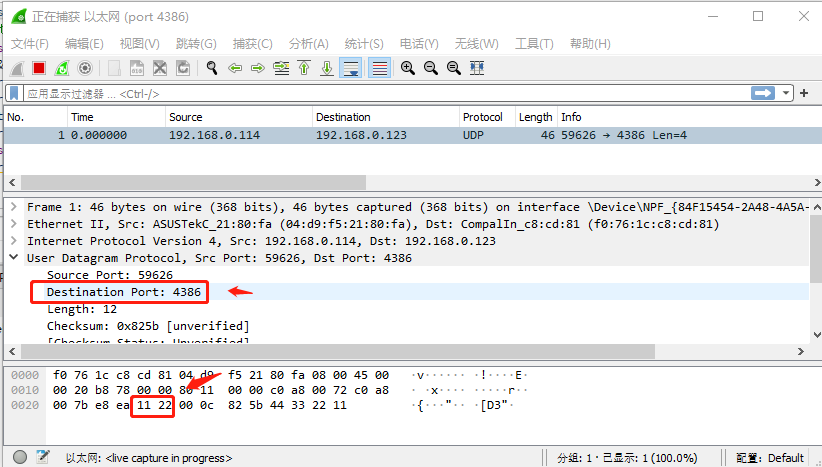
从上图,抓包可以看到,端口号字段 的字节流排序,就是 0x11 22。
UDP client 项目下载:百度网盘,提取码:46p0
这里注意,虽然 UDP 跟 TCP header, RFC标准规定必须是大端排列,但是 TCP body 里面的数据是没有规定的,也就是说,你如果基于TCP 设计一个协议,例如叫 TXP,TXP 的数据是套在 TCP body 里的,TXP 各个字段的内存排列,到底是大端还是小端,这个是由你自己决定的,通信双方约定好使用大端就用大端,用小端就用小端。
假设 规定 TXP 使用小端,前面2个字节是 TXP 协议的version版本号。那么大端序的机器 在发送TXP 的 version 的时候,就需要先把 TXP 的 version 转成小端,再发送到网络里面,就是说 要转成小端套进去 tcp body里面。
发送数据的时候都是发送字节流,他不管什么大端小端,发送只是从内存地址 从左往右 顺序发,发的第一个字节是 0xcd9f37f7f0 的内容,第二个字节是 0xcd9f37f7f1。
然后对面机器接受网络字节流,也是从前到后收,也不管大端小端,第一个收到的字节是 0xcd9f37f7f0 的内容,类推。
所以,大小端字节序,只有在解析数据的时候才又用到,如果不解析数据,那段数据就是一段字节流,不知道每个字段是什么类型,占多少字节,怎么排列,这些事情都是解析的时候做的。
假设对面机器是大端,就需要把 version 的 2 字节内存,重新排序成大端,在赋值或者拷贝内存给 int version,因为网络传输是小端。
如果对面机器是小端,网络传输规定了 TXP 协议是小端,那 2 字节的内存可以直接赋值 给 int version ,不需要转换。
再扩展一个知识,如果你基于 IP 协议,开发了一个 IXP 协议 套在 IP body 里面,这个 IXP 协议是大端还是小端,也是你自己决定的,RFC 标准只是规定了 IP header 必须是大端字节,没规定 IP body 是什么排序。
综上所述,我们编程时候经常用的 inet_addr() , htons(),干的活,就是把 TCP 的header ,UDP 的header 转成大端字节序,再发送,如下:
struct sockaddr_in servaddr;
memset(&servaddr,0,sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_port = htons(5188);
servaddr.sin_addr.s_addr = inet_addr("192.168.0.123");但是大家有没注意到 在做 UDP,TCP 编程的时候,经常用的 recvfrom(),recv(),send(),write() 函数就没有字节序转换的操作。
是不是 send() 内部封装了字节序转换逻辑?
其实不是,上面说了,RFC 只是规定了 TCP header 是大端,没规定 TCP body 是大端还是小端,而 send() 干的活,就是填充内存数据进去 TCP 的body里面。
所以 send() 不需要做字节序转换。
再重复一个重点。
发送数据只管发送,他不管什么大端小端,直接从内存地址 从左往右 顺序发,发的第一个字节是 0xcd9f37f7f0 的内容,第二个字节是 0xcd9f37f7f1,类推。
接受数据只管接受,他也不管什么大端小端,直接从前到后收数据,一个收到的字节是 0xcd9f37f7f0 的内容,第二个字节是 0xcd9f37f7f1,类推。
recvfrom() 拿到 body 的字节流内存数据之后,怎么解析是上层应用自己的事情。
TCP header,UDP header,IP header 的字节序转换,解析,是内核帮你做了,所以不太容易注意到,但是 body 里面的解析要你自己搞。
相关阅读:
由于笔者的水平有限, 加之编写的同时还要参与开发工作,文中难免会出现一些错误或者不准确的地方,恳请读者批评指正。如果读者有任何宝贵意见,可以加我微信 Loken1。QQ:2338195090。