

本系列 以 ffmpeg4.2 源码为准,下载地址:链接:百度网盘 提取码:g3k8
FFplay 源码分析系列以一条简单的命令开始,ffplay -i a.mp4。a.mp4下载链接:百度网盘,提取码:nl0s 。
上一篇文章已经讲完了视频播放线程的内部逻辑,视频同步算法也进行了讲解。
本文开始讲音频同步算法,也就是用-sync video 把同步方式 设置为 AV_SYNC_VIDEO_MASTER。
因为视频是主时钟,所以video_reflesh() 播放视频的时候,compute_target_delay() 什么都没有做。
last_duration = vp_duration(is, lastvp, vp);
delay = compute_target_delay(last_duration, is);delay 等于 last_duration,视频流会按照自身的帧率播放。然后 音频 会向视频进行同步。
接下来讲解音频 是如何向视频同步的。
第8篇文章的时候说过,音频播放是在 sdl_audio_callback() 回调线程里面处理的,当时我没有提及到 synchronize_audio() 这个函数,是因为过早提及会给讲解带来不必要的复杂性。
现在可以仔细分析 synchronize_audio() 这个函数了,因为 音频同步算法 就是 在 synchronize_audio() 里面实现的。
synchronize_audio() 的调用流程如下:

synchronize_audio() 的代码如下,重点我已经红笔圈出来了。其实全部都是重点。
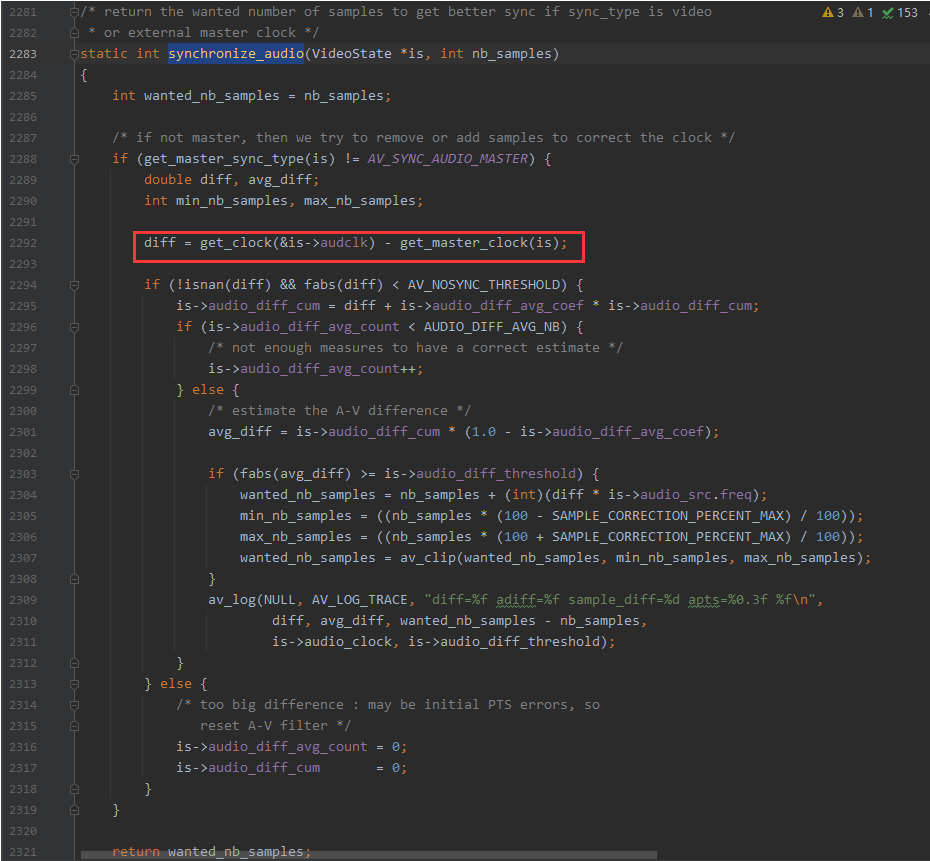
可以看到,跟视频同步一样的套路,先计算出 音频时钟比视频时钟慢多少,或者快多少,也就是 diff。
diff = get_clock(&is->audclk) - get_master_clock(is);然后 对 diff 做了判断,小于 10s 秒内的差异都可以进行同步操作,大于10s就会reset A-V filter了,AV_NOSYNC_THRESHOLD = 10s。
后面的逻辑就比较复杂了,需要先分析一些变量的作用,
audio_diff_avg_count 用来统计音视频不同步的次数,因为callback每0.04s才回调一次,AUDIO_DIFF_AVG_NB 设置为20,也就是至少要有差异20次才开始执行样本补偿算法。
audio_diff_avg_coef 的计算方式如下:
/* init averaging filter */
is->audio_diff_avg_coef = exp(log(0.01) / AUDIO_DIFF_AVG_NB);它首先用 log 求 0.01 的自然对数,除以 20,最后又求指数,自然对数缩写然后求指数,我也不太懂,需要用到这个算法照抄就行,咱们写代码的,数学公式看不懂,变量跟 if 等逻辑肯定能看懂,抄还是可以抄的。
audio_diff_avg_coef 翻译一下,是指 音频 差异 平均 系数,avg 是平均,coef 是系数,这是一个系数变量。
audio_diff_avg_coef 算出来的值是 0.79432。
平均系数变量如何使用?仔细看下面这行代码:
is->audio_diff_cum = diff + is->audio_diff_avg_coef * is->audio_diff_cum;上面这行代码的主要作用是让前面的差异权重越来越小,后面的差异权重越来越大。我把 diff 分为 3次差异讲解。
a_diff 为第一次差异,b_diff 为第二次差异,c_diff 为第三次差异。
is->audio_diff_cum = (a_diff) + (b_diff + 0.79 * a_diff) + ( c_diff + 0.79 * (b_diff + 0.79 * a_diff) )。可以看到,最开始的差异 a_diff 乘了两次 0.79 ,所以a_diff 会变得越来越小,b_diff 乘了一次 0.79,c_diff 还是原来的 c_diff ,c 的权重最大。
所以说,audio_diff_avg_coef 系数是用来进行操作权重的。想一下也合理,后面的差异肯定权重大。
最后 会算出一个 平均 差异 avg_diff。也就是如下代码,is->audio_diff_cum 乘以 0.21。
/* estimate the A-V difference */
avg_diff = is->audio_diff_cum * (1.0 - is->audio_diff_avg_coef);还有一个字段 audio_diff_threshold ,audio_diff_threshold 的赋值是在 audio_open 打开音频设备的时候赋值的。
/* since we do not have a precise anough audio FIFO fullness, we correct audio sync only if larger than this threshold */
is->audio_diff_threshold = (double)(is->audio_hw_buf_size) / is->audio_tgt.bytes_per_sec;可以看到, audio_diff_threshold 实际上等于0.04s,等于一个音频callback的回调间隔。
然后判断 avg_diff 大于一个callback的时间就进行同步,少于不管。跟视频同步也很像,视频是大于一个视频帧的时间才同步。
代码继续跑,跑到下面这句
wanted_nb_samples = nb_samples + (int)(diff * is->audio_src.freq);上面这句代码把 diff 音频落后/快于视频的时候,换算成样本数,增加或者减少原来的样本数,达到拉长声音,或者缩短声音时间的效果。
音频如果快于视频,就把声音拉长,播放得慢一点。
音频如果慢于视频,就把声音缩短,播放得快一点,
快慢不能超过原本样本的 10%。因为声音如果拉得太长,或者缩得太多会很容易听出来。如果 缩短 10% 不足以让音频追上视频,下次还会再缩短10%,拉长同理。
音频同步方式跟视频不一样,不是用丢帧或者重复上一帧实现的,因为音频的连续性太强,音频1秒播放48000样本,视频一秒才播放24帧。
最后得到的 wanted_nb_samples 会传进去 swr_set_compensation() ,因为拉长或缩短音频是重采样函数做的。
最后还有一个知识点想讲解一下。

音频同步代码能拉长或缩短的数据是 len 绿色的部分,但我个人感觉应该立即把红色部分的音频拉长或缩短才能更实时,不过可能是因为音频的连续性很强,拉长绿色部分的音频数据效果也差不多。
我把这种操作称为,样本补偿右移,本来应该操作左边红色的内存,但是SDL没有接口可以操作,只能操作右边绿色的内存。
最后还剩外部时钟同步没分析,
外部时钟的同步。实际上就是用 sync_clock_to_slave() 来搞,取第一帧视频 或第一帧视频的pts 作为外部时钟的开始时间,随后外部时钟随着系统消逝时间递增。
ffplay 源码分析,sdl_audio_callback()音频同步算法分析完毕。
©版权所属:知识星球:弦外之音,QQ:2338195090。
由于笔者的水平有限, 加之编写的同时还要参与开发工作,文中难免会出现一些错误或者不准确的地方,恳请读者批评指正。如果读者有任何宝贵意见,可以加我微信 Loken1。
之前就觉得 audio_decode_frame 里面 为什么还要做一次重采样,明明在audio_thread 中 通过 avfilter 滤波器 做过重采样了
现在明白了,音频往视频同步 会 增加 或 减少 样本数,再次重采样