

C语言有 指针,而 C++ 有引用,那 引用 跟 指针 是不是一个东西,本文会从 汇编的角度 来分析这个问题。
指针代码如下:
#include <iostream>
int main()
{
int a = 999;
int* p_a = &a;
printf("data: %d\n", *p_a);
}
引用代码如下:
#include <iostream>
int main()
{
int a = 999;
int &p_a = a;
printf("data: %d\n", p_a);
}我们用 vs2019 来编译调试一下上面的代码,直接调出来 汇编窗口,如下:
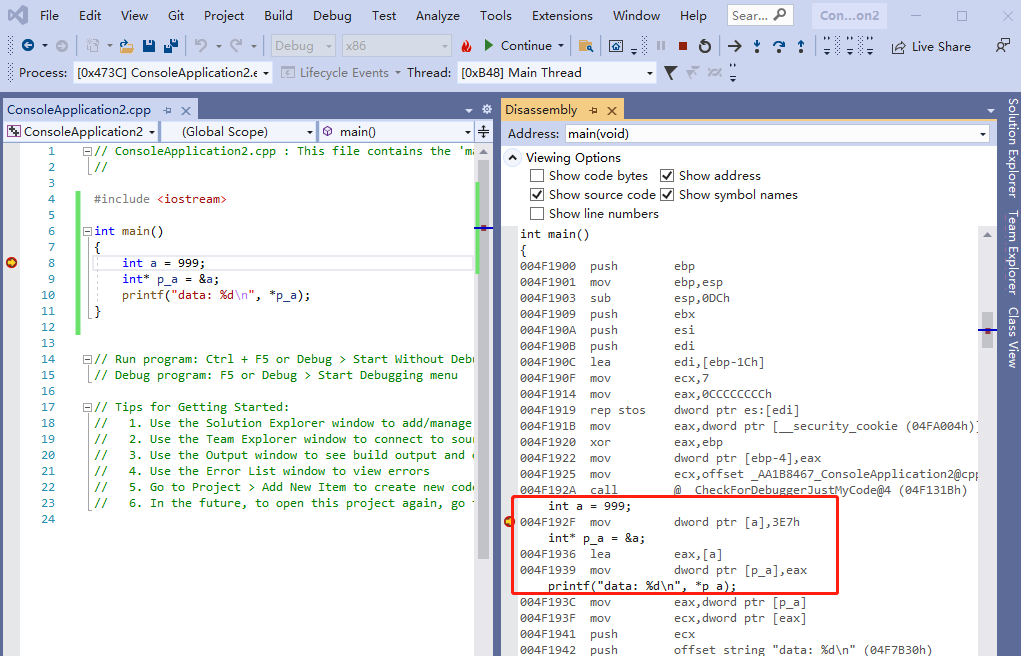
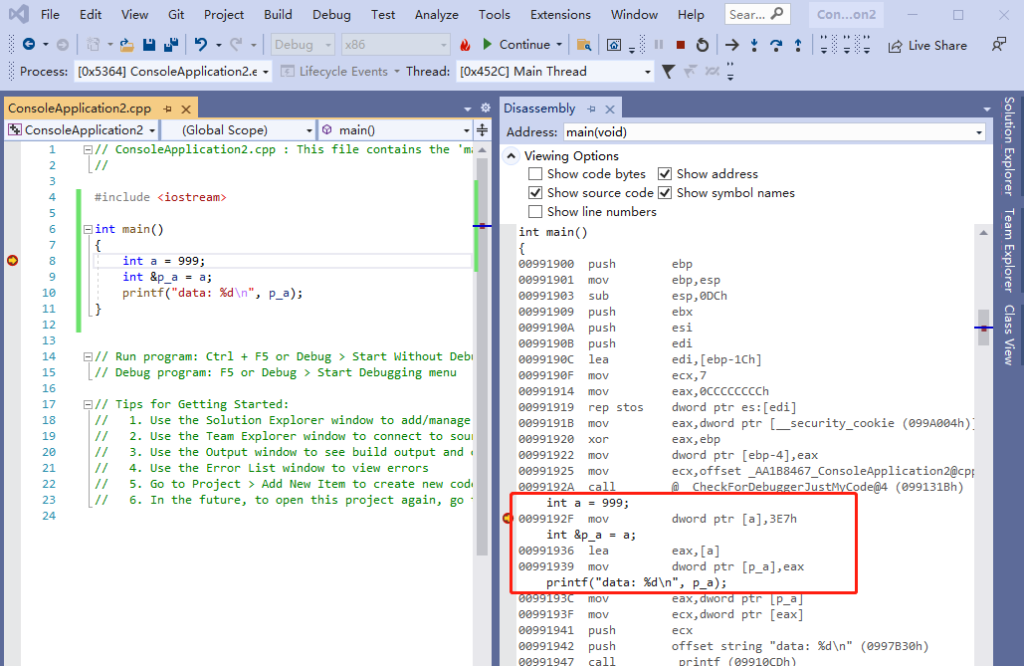
从上面的代码可以看出,引用 跟 指针 编译出来的汇编代码是一样的,汇编代码的功能如下:
1,把 3E7 (10进制是999)复制给 a 变量。
2,把 a 变量的内存地址 复制到 eax 寄存器。
3,把 eax 寄存器的值 复制到 p_a 变量。
下面我们再来看一下,函数里面 用 引用传参 跟 指针传参,生成的汇编代码有什么区别。
指针代码如下:
#include <iostream>
void do_something(int* p_a) {
printf("data: %d\n", p_a);
}
int main()
{
int a = 999;
int* p_a = &a;
do_something(p_a);
}
引用代码如下:
#include <iostream>
void do_something(int& p_a) {
printf("data: %d\n", p_a);
}
int main()
{
int a = 999;
int& p_a = a;
do_something(p_a);
}上面的代码编译之后如下:
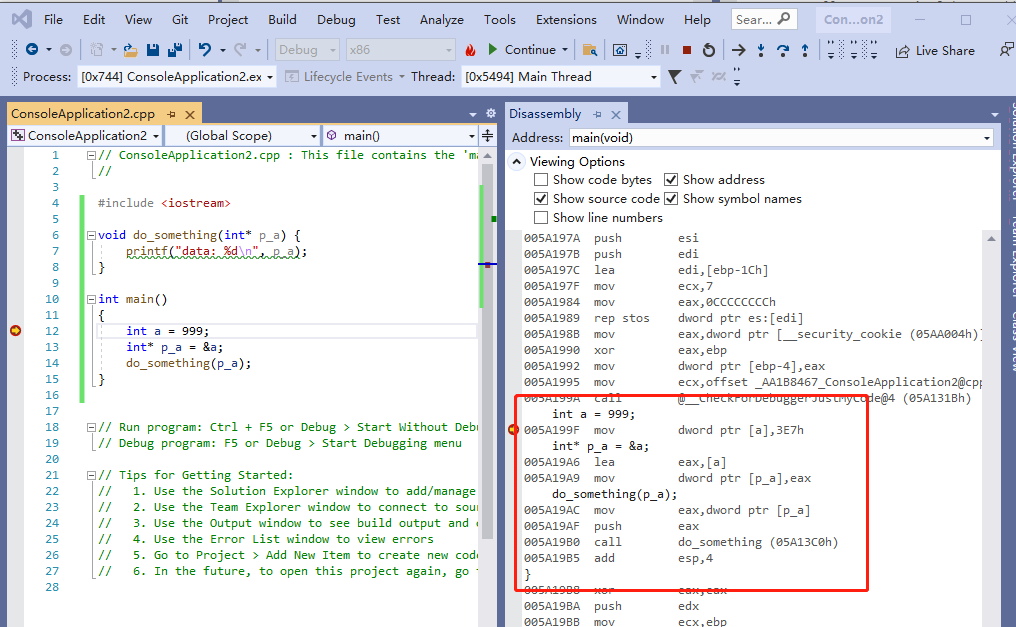
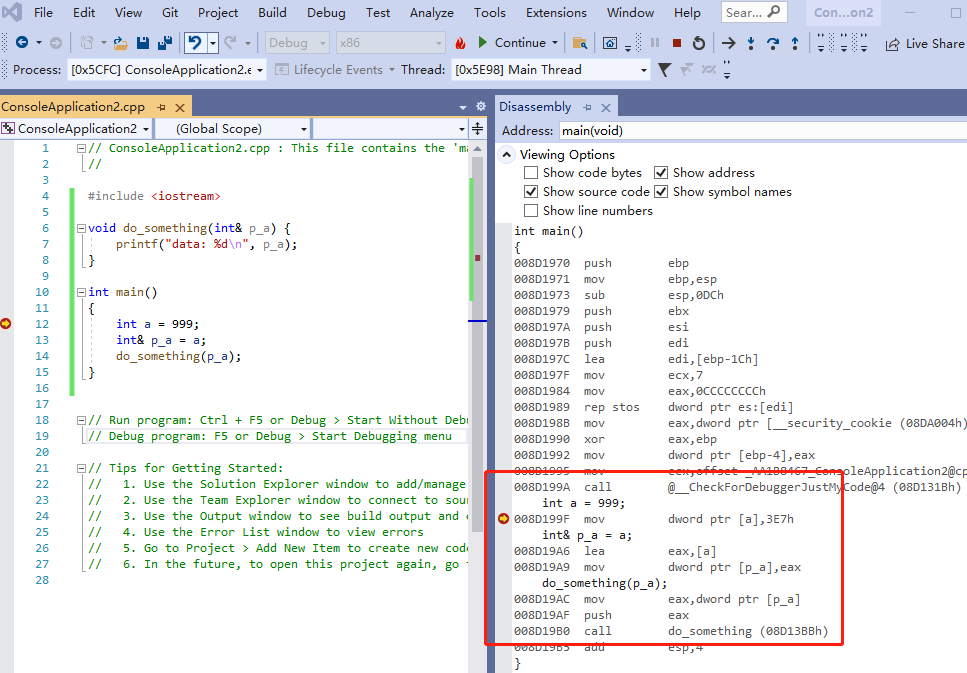
从上图可以看到,生成的汇编代码,依然是完全一样的。所以从汇编的角度来看,引用跟指针实际上就是同一个东西。
引用 跟 指针,更多的是类型系统,编程语言语法 方面的设计,也就是由编译器搞出来的概念,实际上他们最后生成的汇编代码是一样的。
软件程序的底层就是机器码,机器码也叫做 CPU 的指令集。无论是什么样的编程语言,C/C++,RUST,Go,等等,他们能实现的功能,你用汇编一样能实现。
而那些所谓的变量,对象,都只是一段内存数据,CPU指令 就是对 内存数据进行计算,操作。所以 所有类型的变量,或者对象,他们从汇编的角度来看,他们的方法都是一样的,虽然 int 跟 char 在高级语言层面的操作方法不一样,但是他们都是一段内存,从汇编的角度来看,怎么操作都可以。int 变量的内存能进行 X 操作,char 的内存也能进行 X 操作。这里 X 泛指某种操作/方法,例如反转内存。
但是如果你在 C 语言层面随意混用 int 跟 char 的操作可能会导致一些问题,例如 strlen() 函数传了 int 进去。某些混用的场景,会直接导致编译器报错。
所以编程语言语法,类型系统,做的事情,就是限制你随意操作内存,本来你用汇编什么都能干,但是也容易干错很多事情。所以类型系统,编程语法 实际上是对内存使用的一种限制,防止程序员犯错。把运行时错误转换成编译型错误,这样你能提前改正错误。
上面的引用,准确来说 是指 "左值引用",C++ 里面还有一个右值引用的用法,初学者刚学 C++ 会觉得右值引用 非常反人类,不好理解。
本文希望从汇编角度来给读者讲解,如果没用 右值引用,生成的汇编是怎样的,如果用了右值引用,生成的汇编又是怎样的?
从汇编的角度会更容易理解右值引用的意义。
下面截图一下《C++ Primer》对右值引用的阐述。

我们来个最简单的例子,看看右值引用会翻译成什么样的汇编。如下:
#include <iostream>
int main()
{
int&& a = 999;
}提示:不勾选 Show symbol names ,就可以看到最原始的机器码。
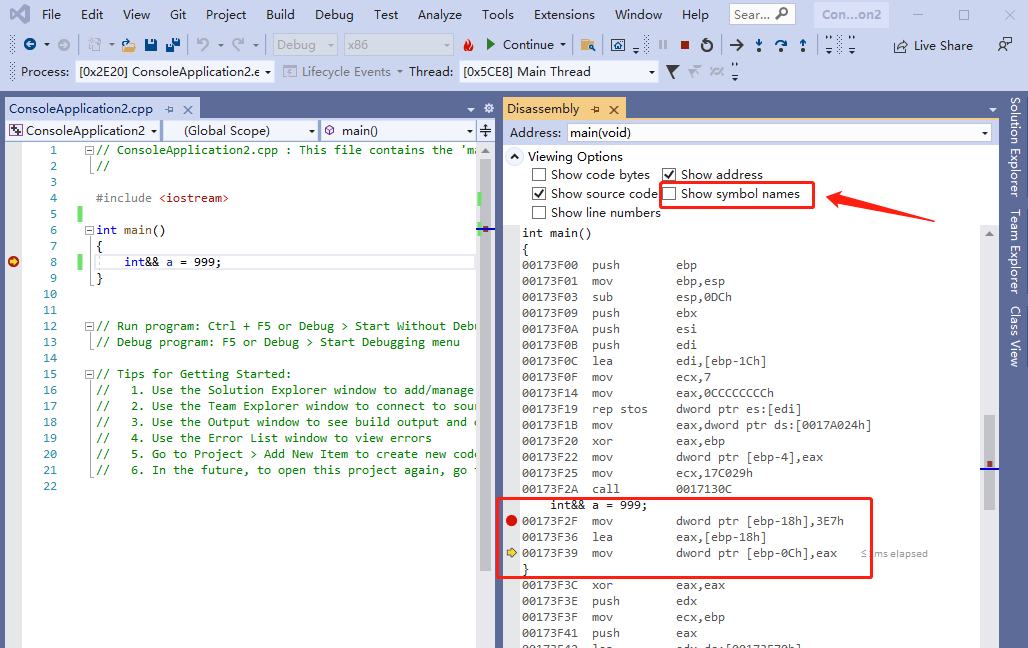
我们可以切换勾选 Show symbol names,会发现上面的 [ebp-0Ch] 实际上就是 a 变量,如下,而 [ebp-18h] 可以看成是一个没有名称的变量。
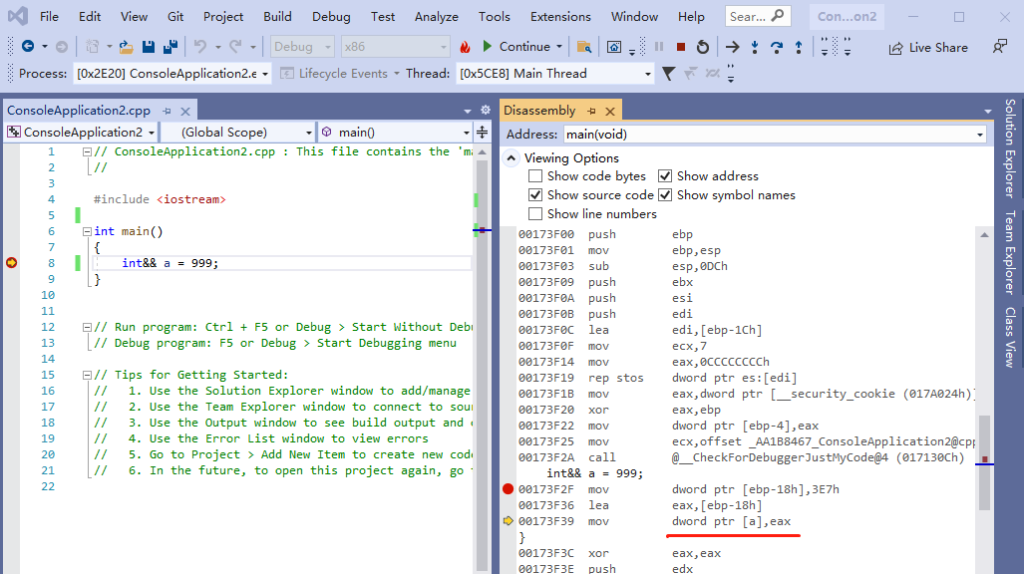
如果我们不用 &&,直接 把 a 赋值为 999,生成的汇编又会怎样呢?如下:
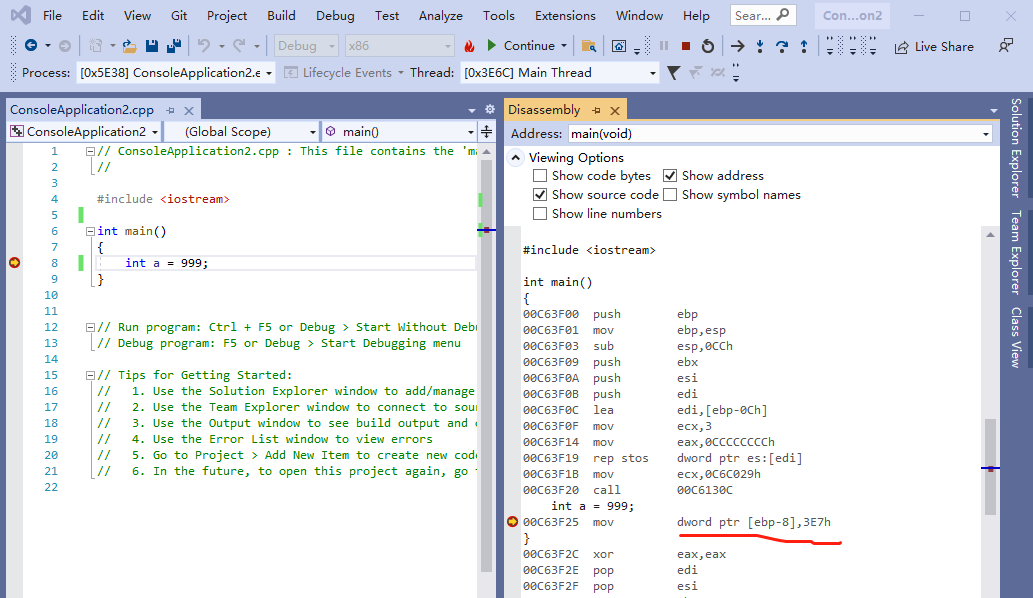
可以看到,两者生成的汇编是有所不同的。
int&& a = 999;
被翻译为 3 句汇编
mov dword ptr [ebp-18h],3E7h
lea eax,[ebp-18h]
mov dword ptr [ebp-0Ch],eax
int a = 999;
被翻译为
mov dword ptr [ebp-8],3E7h对于不熟悉汇编的同学,我先讲解一些这几句汇编的含义。首先。
1,dword 的全称是 Double Word,Word 本身代表 2个字节长度,加上 Double 所以是 4 个字节。
2,ptr 的全称是 pointer ,即指针,
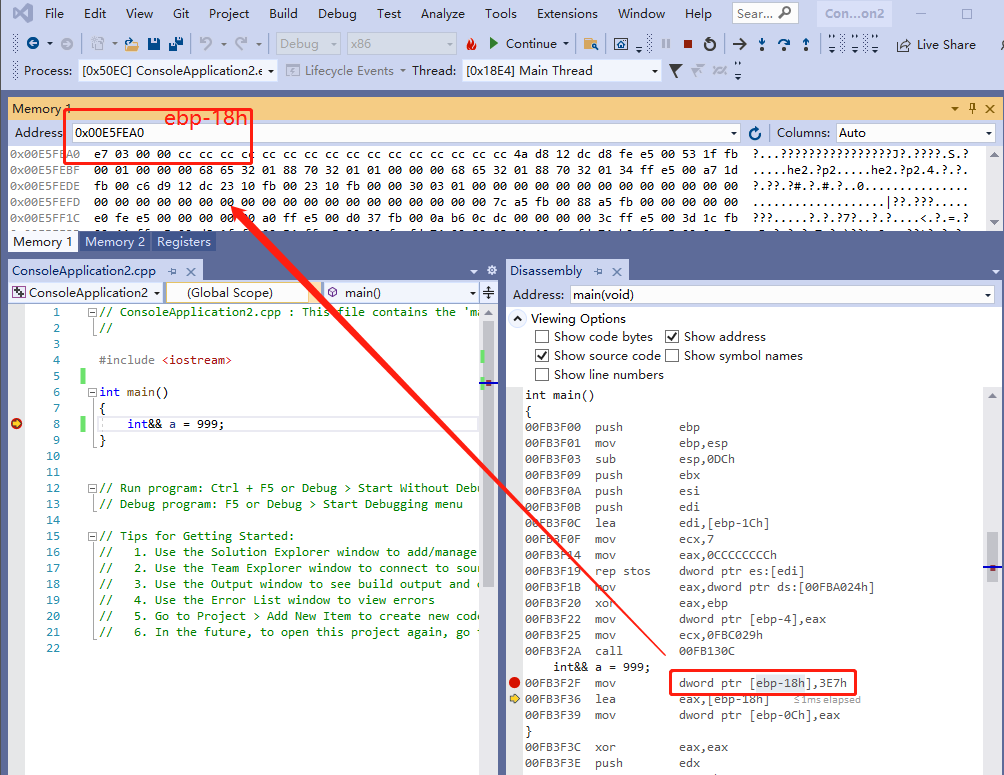
所以 mov dword ptr [ebp-18h],3E7h 的含义就是,把 3E7h 复制到 [ebp-18h] 指向的 4 字节内存的位置。假如 ebp 是 0x00E5FEB8 ,
那 0x00E5FEB8-18h = 0x00E5FEA0 ,那 0x00E5FEA0 ~ 0x00E5FEA3 这 4 个字节的内存数据就是 999。
[ebp-18h] 实际上是一个匿名变量,对比我们刚开始的左值引用例子,int a = 999; int &p_a = a;,右值引用的赋值方法,编译器自己创建了 一个匿名变量。
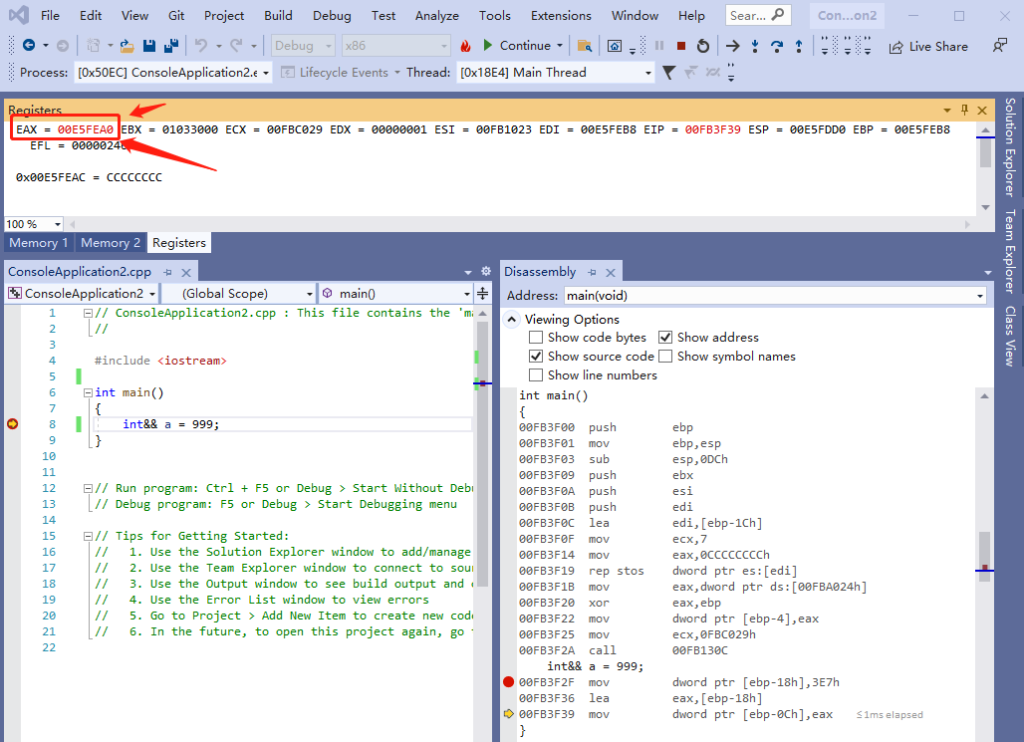
而 lea eax,[ebp-18h] 的意义是把 [ebp-18h] 直接复制给 eax,所以 eax 是 0x00E5FEA0,而不是 999。
从上图可以看出,右值引用最后 还会把 eax 复制给 [ebp-0Ch] ,也就是 0x00E5FEAC 指向的内存。
我们实际调试一下,看下内存数据,如下:
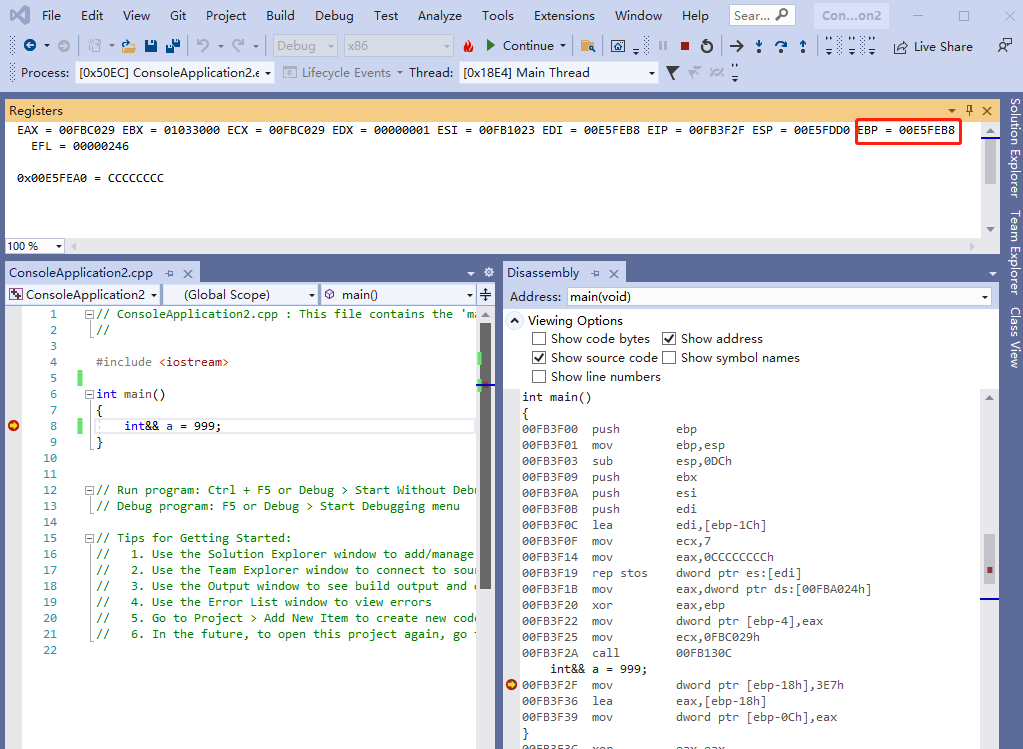
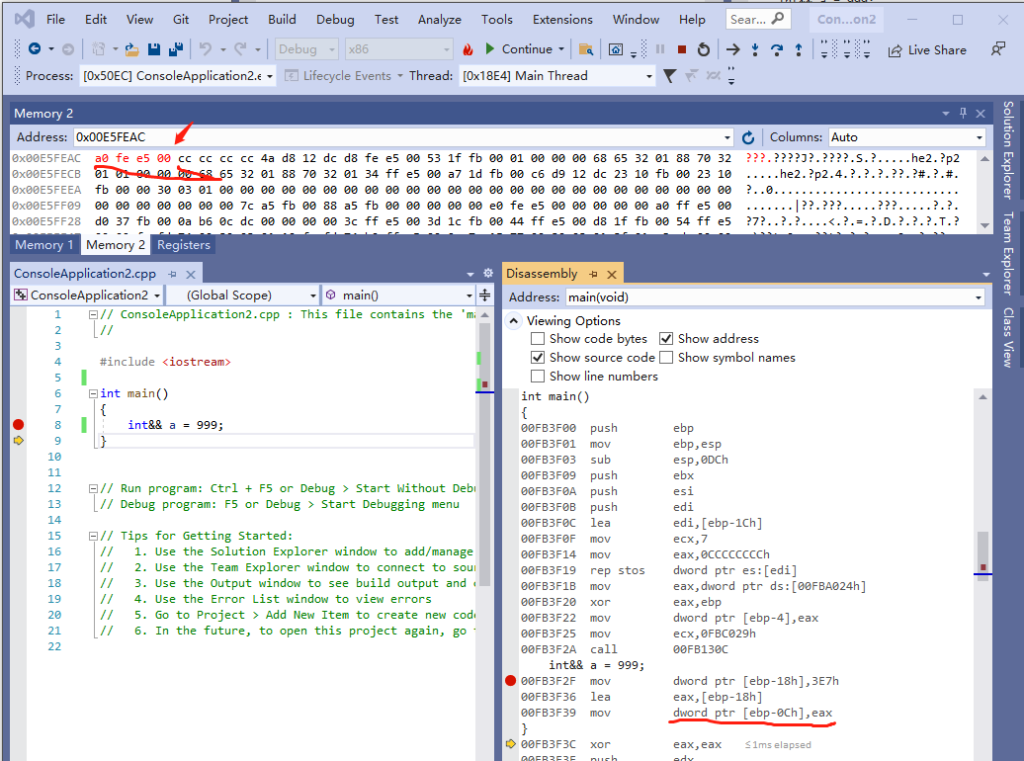
从上图的调试步奏来看,右值引用里面,变量 a 是 [ebp-0Ch] ,也就是 0x00E5FEAC ,而 0x00E5FEAC 指向的内存不是 999,而是 0x00E5FEA0,而 0x00E5FEA0 指向的内存数据才是 999。
如果我们不用右值引用,变量 a 是 [ebp-8],[ebp-8] 指向的内存就是 999。
所以右值引用实际上是什么呢?实际上就是一级指针,为了验证这个事情,我们把右值改成 一级指针写法,代码如下:
#include <iostream>
int main()
{
int nobody = 999;
int* a = &nobody;
}上面,我定义了一个 nobody 变量,来模拟 右值引用里面 编译器自己创建的 匿名变量。编译调试结果如下:
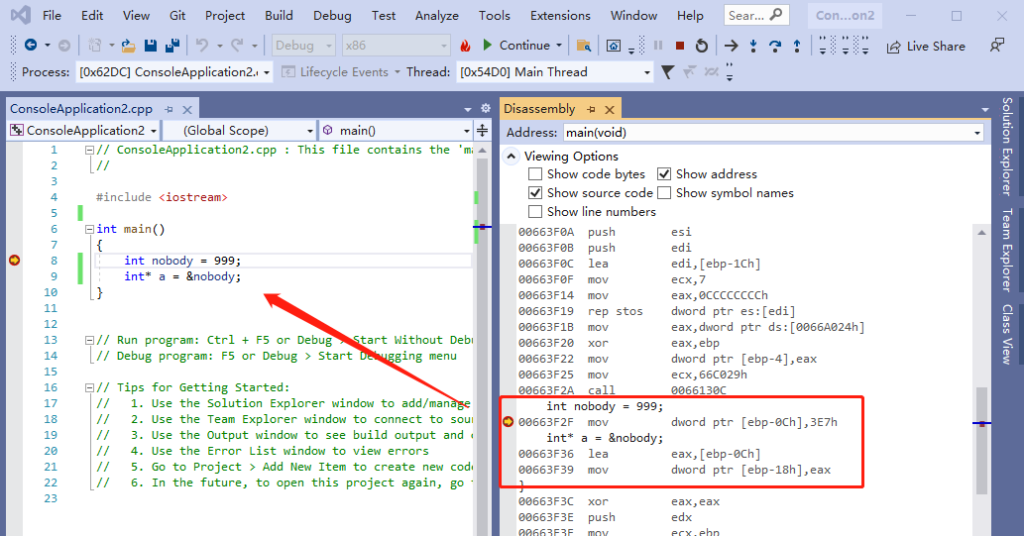
可以看到,一级指针 生成的代码,跟 右值引用是几乎一样,只是变量在栈的位置不太一样,一个向上,一个向下,这个无关紧要。
现在,我们得出结论,右值引用 的底层逻辑,就是一级指针。
扩展知识:《C++ Primer》提到 右值是临时现象,实际上指的就是那个 nobody 匿名变量,没有名称的变量。
我们再来看右值引用的一个复杂的例子,C++ 提供了 std::move(),我们用这个 move 函数来演示,代码如下:
#include <iostream>
class Box
{
public:
int length; // 盒子的长度
int breadth; // 盒子的宽度
int height; // 盒子的高度
};
int main()
{
Box b1;
b1.length = 10;
b1.breadth = 20;
b1.height = 30;
Box b2 = b1;
b1.length = 55;
printf("b2.length = %d \n", b2.length);
}上面的代码运行如下:
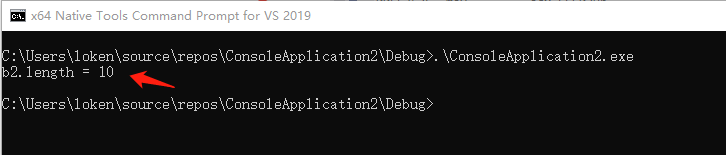
可以看到,b2 并没有受到 b1 赋值的影响,所以 b2.length 等于 10,而不是 55。因此 b1 变量 跟 b2 变量实际上是两块不同的内存。这叫做拷贝赋值
下面我们用 std::move() 来赋值 b2 ,如下:
#include <iostream>
class Box
{
public:
int length; // 盒子的长度
int breadth; // 盒子的宽度
int height; // 盒子的高度
};
int main()
{
Box b1;
b1.length = 10;
b1.breadth = 20;
b1.height = 30;
Box&& b2 = std::move(b1);
b1.length = 55;
printf("b2.length = %d \n", b2.length);
}运行如下:

可以看到 b2 受到了 b1 赋值的影响,所以他们已经指向同一块内存数据。
实际上上面的代码等价与 一级指针的写法,如下:
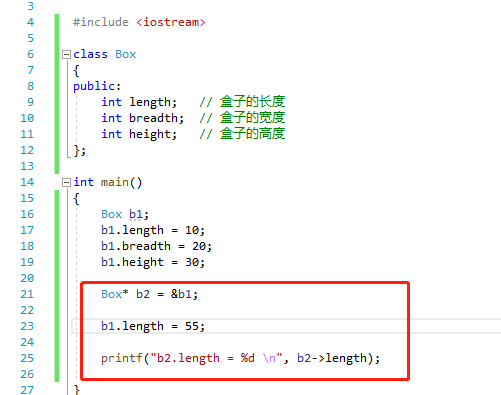
所以右值引用 ,move 函数的本质是什么呢?实际上就是取地址,复制地址,减少拷贝。
我个人的理解是这样的,虽然 C++ 是兼容 C 语言的,所以你可以用 一级指针,二级指针,但是 C++ 委员会貌似一直想在 C++ 里面去掉 指针的用法,所以他们发明了 右值引用 跟 move,实际就是为了 区分 拷贝 跟 移动 这两个操作。移动实际上就是取地址,然后把地址放到另一个变量。
所以可以把 右值引用 看成 是指针的替代品。但我个人认为,指针比右值引用容易使用很多。
由于笔者的水平有限,文中难免会出现一些错误或者不准确的地方,恳请读者批评指正。如果读者有任何宝贵意见,可以加我微信 Loken1。
懂了,感谢博主