

CPU芯片里面通常集成多级缓存,L1缓存,L2缓存,L3缓存,如下:
可能有人会比较疑惑,L0 缓存去哪里了?我们程序员不应该都是喜欢从 0 开始的吗?答案是 L0 缓存实际上就是那 x86-64 架构的那 16 个通用寄存器,rax,rbx 等等。
L0,L1,L2,L3,其实都可以把他们看成是一个高速缓存,他们其实都是内存,只不过 L0 寄存器缓存是最快的,只需要 0个周期就能访问到。不要把寄存器看成是 CPU,要把寄存器看成是一个超高速内存,虽然很小,只有 16 * 64 位大小。
这里讲一个扩展的知识点,离CPU 执行单元最近的内存访问最快,寄存器内存里CPU最近。这是因为物理世界任何东西的传输都有一个速度,光速,音速等等,电子在电路板也有传输速度。比如,一个快递从北京一环送到 二环,是不是比送到五环快?
各个内存层次的访问速度如下,摘自《深入理解计算机系统》
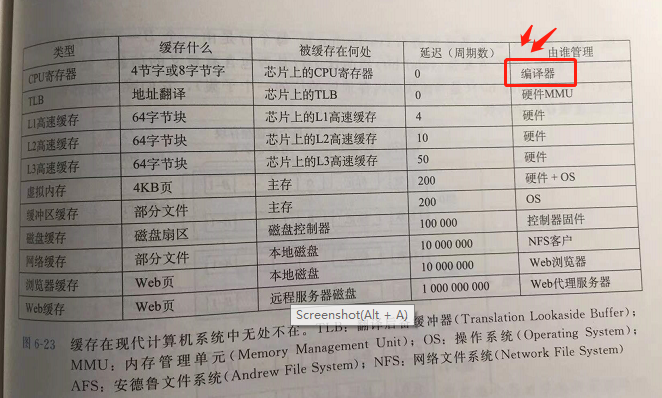
本文的重点是:寄存器 是一个超高速内存
C程序里面主要有以下几种东西。
1,局部变量。
2,全局变量。
3,函数调用里面的函数传参。
上面这些变量 都是 data,这些 data 到底是放在寄存器里面被使用,还是放在内存里面被使用,取决于编译系统的编译规则。举个例子:
int main() {
/* 寄存器传参 */
__asm__("movq $10,%rax");
__asm__("movq $314159,%rsi");
__asm__("mulq %rsi");
/* 内存传参 */
__asm__("movq $10,%rax");
__asm__("movq $314159,%rsi");
__asm__("movq %rsi,(-8)(%rbp)");
__asm__("mulq (-8)(%rbp)");
}上面的代码可以用 这个命令编译 gcc -o main main.c -g。
上面的代码是把某个参数,参数 π (314159),放在 寄存器 rsi 被后面的指令访问。另一种方式是 寄存器不够用,要把 rsi 让出来,只能把 π 放在 (-8)(%rbp) 的位置。
最后 用 mulq 指令把 π 乘以 10,存在 rax 里面。 第一种方式 mulq 指令是从 L0超高速内存 寄存器 里面取的 π,第二种方式是 从 L1 缓存取的,如果L1缓存找不到,就会从 L2 取,最后一直找到内存条那里。
从上图我们可以知道,从寄存器取π 不需要CPU周期,如果从L1取要4个CPU周期。
由于笔者的水平有限, 加之编写的同时还要参与开发工作,文中难免会出现一些错误或者不准确的地方,恳请读者批评指正。如果读者有任何宝贵意见,可以加我微信 Loken1。QQ:2338195090。