

由于本人做互联网各种业务系统开发有9年左右的时间,所以讲一些常见的场景来设计缓存。
假设,设计一个类似小红书的app,后端缓存应该如何设计。这里不直接讲最后的架构,而是讲 产品 周期,架构的迭代的过程以及各种思考策略。
首先产品前期是不会做 缓存层的设计的,因为互联网业务是复杂多变的,一个初期平台流量是不太大的。今天做一个需求,上线3天后可能就下架了,老板会催产品经理,然后产品经理再来催你。所以功能要尽量上线,老板跟产品经理都不知道这个模块流量大不大,大了你再优化嘛。这个是初期平台的情况,有些大平台本身就有流量积累,例如微博,微信,每上线一个功能,都立马有很多人试用。这个是与小平台的差异所在,小平台你上线个新功能,零零碎碎的访问,无人问津。
大平台上线新模块,一推广服务器挤爆。所以大平台而言,一开始就需要设计缓存层。
所以小平台产品,初期通常只会做数据库读写分离,提高一下处理能力,以 PHP + MYSQL 举例,因为后端业务通常有很多HTTP接口,选一个最复杂的接口来测试,这个接口只做了查询操作,没有插入,没有写操作。所以可以负载到各个 从库,不需要操作主库。
这个接口 在 PHP + MYSQL 的架构下响应速度是 100ms ,所以处理完这一个HTTP请求需要 100ms,也就是1秒钟可以处理10个请求,我假设这个是单核CPU的情况,扩展到多核,最理想的情况,倍速递增 ( 通常不会是倍速递增,进程总有一些互斥操作 ),我这里是假设最理想的情况,真实情况需要结合具体的业务代码压测。扩展到 16核机器,PHP + MYSQL 架构能一秒处理 160个请求,通常不会这么理想,我折中一下,一秒处理80个相同的HTTP请求。
然后,加10台PHP应用服务器,10台MYSQL 从库,负载均衡之后,系统的处理能力是1秒800个请求,但是考虑到前端的一个功能模块不会只请求一个接口,所以在现实业务中,这种架构扩展之后,大概能容纳200人左右同时访问系统。
这就是小平台初期的处理能力的设计,因为没有缓存层,所以比较能适应复杂多变的业务。
上面讲的是读操作的负载均衡,一般业务系统都会有写操作,写操作需要操作主库,多主架构本人没有在实际场景用过。所以不讲多主架构。主库只有一个就会形成单点瓶颈,所有的业务都需要往主库写。这种情况可以用 rabbitmq 之类的消息队列,把任务弄成是异步处理。但是所有业务都往 rabbitmq 写,rabbitmq 后面也会是单点,这种情况可以用分布式库存,例如总后台 1万个库存,每台服务器分100个,开100个服务器,库存放在本地redis里面,有100个redis,这样服务器跟服务器就不会阻塞,然后再开一个后台进程,定时同步redis的订单到 rabbitmq,然后总后台来消费 rabbit mq。这里需要前端做下处理,因为redis的订单是伪订单,只是有一些必要的字段,可以只能看,告诉客户抢到了,但是不能做其他的操作例如退款,修改订单联系人等等。因为真正的订单还未生成。
PHP+MYSQL+本地redis,就能把所有写操作负载到各个服务器。整体的架构如下图:
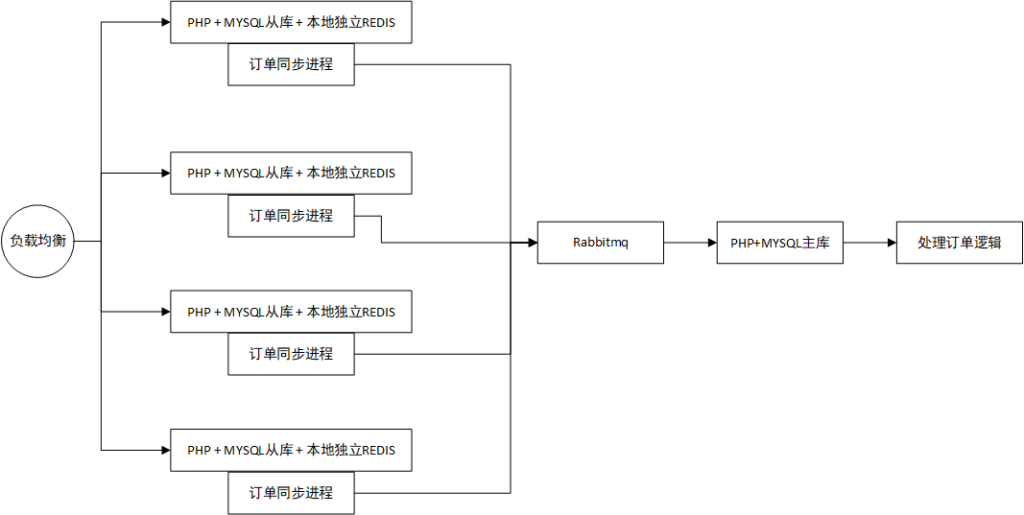
前面的架构背景讲完了,通过 部署多个 MYSQL从库,也能扩展读能力,为什么还需要设计 缓存层,缓存层通常 用 redis 实现。首先提及一点,mysql 本身也有缓存设计,推荐阅读 《MySQL缓存机制》。
首先,mysql 的缓存是一个通用设计,有一个问题,他的缓存不分析查询语句,如果表被 修改了所有缓存失效,这个是mysql早期的版本,具体我也不知道是哪个版本。最新的mysql 版本的查询缓存可能会分析查询语句,这个要看代码或者chanelog,反正 mysql 某个版本的缓存机制是这样,表修改了所有缓存失效。
这个会导致一个什么问题,例如 你的业务只需要查 id,name,loaciton,只需要查名称跟地址,不需要查age 年龄。本来别的业务修改了 age 字段,你的缓存可以继续用,但是 mysql 会把缓存置为失效。
这个时候,如果你用 redis 自己做表缓存就可以自定义这些东西。用 redis 来做表缓存 通常有几个做法。
1,mysql的表名后面加 _cache,说明这个表需要通过 缓存类 来操作,修改这个表,要通知更新相应的缓存。也说明这个表的部分数据缓存在 redis,可以通过缓存类进行高速查询。
讲个简单的例子,MYSQL数据库有 3千万篇文章,但是热门访问的文章是1000篇,如果直接查数据,查询如下:
SELECT id,post_name FROM `wp_posts` WHERE id = 105;从 3千万数据里面查询一条记录,我不清楚 mysql 的内部数据结构,除非这整个查询过程用到的所有算法是 O(1) 的,也就是查询速度不会随着数据量上升,但是这通常不可能。你弄个 表,只有100条数据查询,数据增加到1千万,查询速度会降低30%左右。hash算法是 O(1),但是数据量多了也会碰撞 hash,总之过程很复杂。真实的情况就是,数据量多,mysql 查询速度就会有一定的程度降低。
所以可以针对这种情况做redis缓存,把 1000 篇文章放在redis缓存里面,上限是1000篇,具体可以用 hash 跟 链表来实现,hash 可以直接定位到数据,链接是用来记录缓存访问量,排序的,容器到了1000篇,就把低访问量的文章踢出缓存。
这个是 redis 缓存的一个简单的场景,redis 缓存非常容易扩容,因为只有1000条数据,如果扩容 mysql 从库,3千万篇文章都要拷贝一次,非常耗时间。所以 redis 缓存层的优势之一就是数据少,可以快速扩容。
还有一些其他场景的环境设计可以仔细研究,主要都是根据 where 条件,查询字段来做相应的业务缓存。不过切记不要设计得太细,各种语法分析都用上没必要,redis缓存层,就是根据业务设计的,不需要跟mysql的查询缓存相提并论,mysql的查询缓存是分层设计,redis 缓存本身就是业务层,所以设计得太细也会影响开发效率。需要根据具体业务做权衡。
由于笔者的水平有限, 加之编写的同时还要参与开发工作,文中难免会出现一些错误或者不准确的地方,恳请读者批评指正。如果读者有任何宝贵意见,可以加我微信 Loken1,QQ:2338195090。