

lookupdns 只有 300 行代码,但是却演示了 如何使用 协程 并发请求 dns。
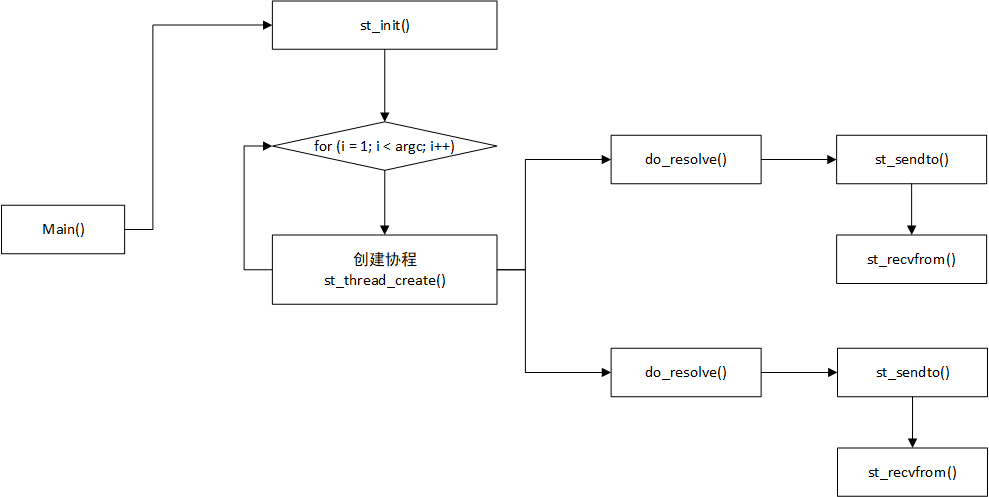
lookupdns 的流程图如下:
编译之后,运行以下命令:
./obj/lookupdns www.xianwaizhiyin.net www.baidu.com上面两个命令 用协程 查询了两个域名,wireshark 抓包如下:
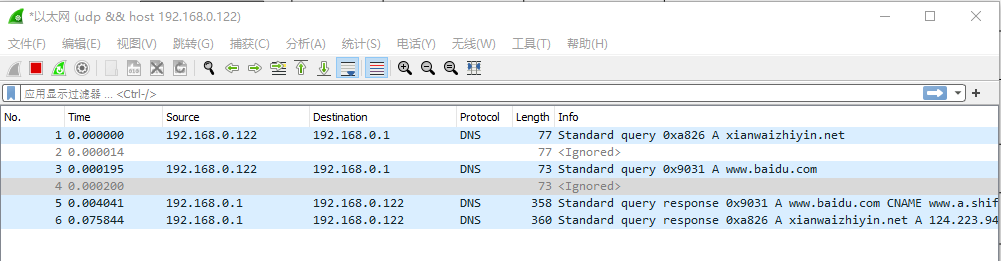
从数据包上看,两个 udp 查询,是并发的,第二个请求并没有被第一个请求阻塞。st_recvfrom() 函数只会阻塞当前的协程,并不会阻塞第二个协程。而且 这两个协程 是在 同一个线程里面的。这就是 协程的精髓。
我们如果用原生的 udp 来写,伪代码如下:
int socket_fd1 = socket(PF_INET, SOCK_DGRAM, 0)
sendto(socket_fd1,www.xianwaizhiyin.net)
// recvform 会阻塞。
recvform(socket_fd1)
int socket_fd2 = socket(PF_INET, SOCK_DGRAM, 0)
sendto(socket_fd2,www.baidu.net)
// recvform 会阻塞。
recvform(socket_fd2)如果上面这种写法,请求之间会阻塞,如果想不阻塞。可以使用操作系统的 线程函数,pthread_create()。但是创建线程需要一定的开销,而且不可能查询1000个域名就开1000个线程。如果不使用 pthread_create 是不是就无法并发请求了?不是,操作系统其实本身也有 EDSM(事件驱动模型),就是 epoll ,select/poll 函数。
用 epoll 实现 udp 单线程并发请求的伪代码如下:
int socket_fd1 = socket(PF_INET, SOCK_DGRAM, 0)
sendto(socket_fd1,www.xianwaizhiyin.net)
int socket_fd2 = socket(PF_INET, SOCK_DGRAM, 0)
sendto(socket_fd2,www.baidu.net)
//监听两个 fd 的变化
epoll(socket_fd1,socket_fd2)
//变化到了,循环调 recvform()
recvform(socket_fdx)上面的代码,我是用了 epoll 来监听两个 fd 的变化,所以两个请求不会阻塞。
那么问题来了,既然操作系统本身就有类似的功能,为什么还需要 state-thread?
问题1:是不是 state-thread 比 操作系统的 EDSM 快?
解答1:不是,从性能上来说,ST和传统的EDSM实现一样快。上下文切换的开销是进行 setjmp()/longjmp()的成本(不涉及系统调用)。这对于所有的实际应用来说是可以忽略不计的。创建线程的开销也非常小。
Performance-wise ST is as fast as traditional EDSM implementations. The context switch overhead is a cost of doing
_setjmp()/_longjmp()(no system calls are involved). This is negligible for all practical applications. The thread creation overhead is also very small.
问题2:是不是 state-thread 在 内存使用效率上 比 操作系统的 EDSM 高?
解答2:也不是,在内存方面,ST几乎和传统的EDSM一样高效。尽管在 ST协程 创建时为整个堆栈段保留了交换空间,但只有实际使用(触及)的堆栈页会被带入物理内存。然而,每个 ST协程 有一个页面的最小内存要求。在任何情况下,无论是ST还是传统的EDSM,执行状态都必须被存储在某个地方。把它保存在堆栈中,比在特设数据结构中更有效。
Memory-wise ST is almost as efficient as traditional EDSMs. Although the swap space is reserved for the entire stack segment upon thread creation, only stack pages that are actually used (touched) will be brought into physical memory. There is, however, one page per thread minimum memory requirement. In any case -- ST or traditional EDSM -- the execution state has to be stored somewhere. Keeping it on the stack is much more efficient than in ad hoc data structures.
既然 state-thread 性能 ,内存的角度都不比 传统的EDSM 高效,那 state-thread 的优势在哪里呢?
1,用 state-thread 写的代码比较通俗易懂,因为 epoll 的架构 会把 request (请求) 跟 response (回调) 分离,上面第一版阻塞型的 udp 是不是比 第二版的 epoll 的udp更易懂。这种 请求 跟 回调 分离 的架构,简单业务看起来没多大影响,但是如果你基于TCP 实现一个RTMP 的协议,就会发现 epoll 这种 回调 跟 请求分离的写法特别麻烦,因为 RTMP 是复杂的协议,要经过多次数据包交换才能建立 RTMP链接。每个包都是一个状态变更,在需要回源时,这个状态会呈指数增长,多到无法处理。
但是,你看 state-thread,他的 st_sendto() 之后,可以立即执行 st_recvfrom(), st_recvfrom() 并不像 操作系统的 recvform() 一样,会阻塞线程的其他任务,st_recvfrom() 只会阻塞当前协程,不会阻塞同一个线程中其他的任务。这样就能把 请求 ,跟对面的 respond (回调)合在一起,顺序处理,代码看起来是顺序的。这样 实现 RTMP 这种复杂协议,因为是顺序的,所以写起来就比 epoll 简单很多。
由于ST 库本身是单线程的,单线程里面创建多个协程。所以如果想充分利用多核系统的性能,可以使用 多进程 + 多协程的模式。
例如,要查询 8000 个域名的IP,在4核机器上,就可以 fork() 创建 8 个进程,每个进程里面查询一个域名就调 st_pthread_create() 创建一个协程来查询,这样不会阻塞,也不需要用 epoll,每个进程查询不同的位置,进程A 查 1~1000,进程B 查 10001 ~ 2000,类推。这样能避免竞争资源。
为什么 4核 创建 8个进程,因为双倍于核心的进程是最有可能达到 底层 指令并行执行的情况。
多进程 + 多协程 是 ST 官网比较推荐的架构,因为机器上,不可能只运行一种任务的线程,肯定有其他不同种类的任务需要处理,举个例子,订单逻辑 跟 广告逻辑 是两个不同的进程。不同种类的任务分开进程,能防止同步的损耗。
这里面涉及到一个系统扩展性的问题,就是你的程序,2核CPU上,能跑100个并发。扩展到 4 核CPU,就应该嫩跑到 200 并发。但是如果你的多进程,或者说多线程之间需要同步的资源太多,扩展性会降低。4核 CPU 也许只能跑到125个并发。
loopupdns 的程序比较简单,到这里已经讲解完毕了,ST协程的优势 也顺带讲了。下一篇文章开始讲 ST 协程的实现。
由于笔者的水平有限, 加之编写的同时还要参与开发工作,文中难免会出现一些错误或者不准确的地方,恳请读者批评指正。如果读者有任何宝贵意见,可以加我微信 Loken1。QQ:2338195090。