

几乎每个做应用开发的工程师,学习汇编的时候,都会遇到这样一个困惑,各种汇编书籍,例如《汇编语言 基于x86》《现代x86汇编程序设计》这些书籍都是讲 汇编指令 在单核里面的情况。我们做应用开发的时候是经常用到多线程的,而我们的C/C++ 代码最后是翻译成汇编的,虽然 pthread_create 函数是操作系统提供的函数,但是操作系统本质上也是一条一条汇编指令堆叠而成。所以做应用开发的工程师 基本都有这样一个好奇心,操作系统提供的多线程的汇编实现是怎样的,他是怎么调度不同的线程的汇编指令到不同的CPU核心上运行的?
首先,Linux 创建线程的函数是 pthread_create(),实际上这是 glibc 库的一个函数,glibc 是 类Linux 操作系统的核心库,是用C语言写的,这个库根据各种标准 ISO C11, POSIX.1-2008, BSD, OS-specific APIs,提供了一系列的函数实现,例如我们经常用的 open, read, write, malloc, printf, getaddrinfo, pthread_create, 等等函数,都是这个库实现的。
下面就来看下 pthread_create() 函数的内部实现,使用的 glibc 版本是 2.27 ,pthread_create 函数的实现在 glibc-2.27/nptl/pthread_create.c,如下:
其实在这里,我特别推荐大家先看一遍 state-thread 的协程实现,因为协程跟线程的实现非常类似。《state-thread源码分析》,ST协程可以很轻易地在 linux 环境下调试,有助理解线程的实现,线程只能调试操作系统内核,比较麻烦。
pthread_create 函数的代码如下(部分代码已省略):
__pthread_create_2_1 (pthread_t *newthread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg)
{
STACK_VARIABLES;
const struct pthread_attr *iattr = (struct pthread_attr *) attr;
struct pthread_attr default_attr;
struct pthread *pd = NULL;
int err = ALLOCATE_STACK (iattr, &pd);
int retval = 0;
/* Store the address of the start routine and the parameter. Since
we do not start the function directly the stillborn thread will
get the information from its thread descriptor. */
pd->start_routine = start_routine;
return retval;
}
versioned_symbol (libpthread, __pthread_create_2_1, pthread_create, GLIBC_2_1);可以通过 gdb 反汇编看 pthread_create 最后的汇编代码。
可以看到,线程的创建跟 ST 协程的创建是比较类似的,在 pthread_create 实际上看不出来 操作系统是怎么把不同线程分配到不同核心运行的。因为还未开始调度,线程还未开始执行。
所以真正的代码其实在操作系统的调度函数里面,操作系统的调度代码我还未看,但是猜测一下,操作系统应该是用了某个汇编指令把不同线程的汇编代码载入不同核心的L1缓存。然后CPU核心各自从 L1 指令缓存拿数据来运行,实际上可能是这样,指令寄存器 EIP 只有一个,但是 EIP 是一个地址,如果EIP 执行指令如果在核心A的 L1 缓存,核心A 就会运行。所以不同的核心 肯定是有各自 的 EIP 副本,主 EIP 只有一个,但是副本有多个。
纠正:多核CPU,每个核都有一个EIP 寄存器的。
如下:
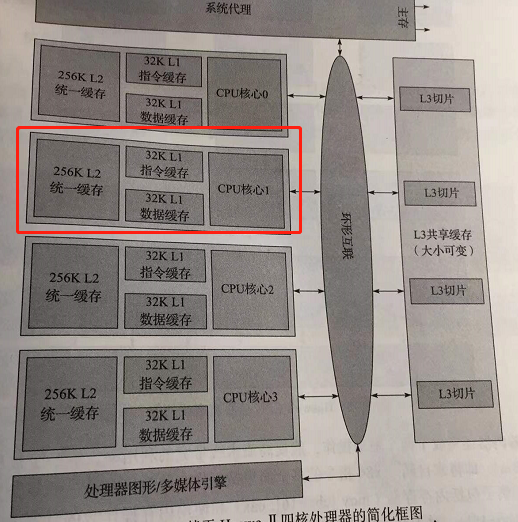
具体的知识应该在《现代操作系统》《计算机体系结构》《深入理解计算机系统》里面,等我看完再完善这篇文章。
我们知道,在 linux 环境用 C 语言写程序的时候,可以使用多线程提高软件的处理能力,也就是 pthread_create() 函数,C语言多线程代码如下:
#include <pthread.h>
int add_two(int a,int b){
return a+b;
}
void* thr_fn(void *arg)
{
add_two(1,8);
return NULL;
}
int main( void )
{
pthread_t ntid;
int err = pthread_create(&ntid, NULL, thr_fn, NULL);
return err;
}我们还知道,C语言 会被 gcc 翻译 成汇编,那汇编 里面有没有 多线程 相关的指令呢?
带着这个疑问,我们用以下命令把 C 语言转成汇编。
gcc -S -o main-thread.s main-thread.c生成的 64 位汇编代码如下,因为是 64位的 有些寄存器是 rsp,不是 esp。
.file "main.c"
.text
.globl add_two
.type add_two, @function
add_two:
.LFB5:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %edx
movl -8(%rbp), %eax
addl %edx, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE5:
.size add_two, .-add_two
.globl thr_fn
.type thr_fn, @function
thr_fn:
.LFB6:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $8, %rsp
movq %rdi, -8(%rbp)
movl $8, %esi
movl $1, %edi
call add_two
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE6:
.size thr_fn, .-thr_fn
.globl main
.type main, @function
main:
.LFB7:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $32, %rsp
movq %fs:40, %rax
movq %rax, -8(%rbp)
xorl %eax, %eax
leaq -16(%rbp), %rax
movl $0, %ecx
leaq thr_fn(%rip), %rdx
movl $0, %esi
movq %rax, %rdi
call pthread_create@PLT
movl %eax, -20(%rbp)
movl -20(%rbp), %eax
movq -8(%rbp), %rdx
xorq %fs:40, %rdx
je .L7
call __stack_chk_fail@PLT
.L7:
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE7:
.size main, .-main
.ident "GCC: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0"
.section .note.GNU-stack,"",@progbits上面的代码,最精髓的是下面截图出来这一行,请看下图:
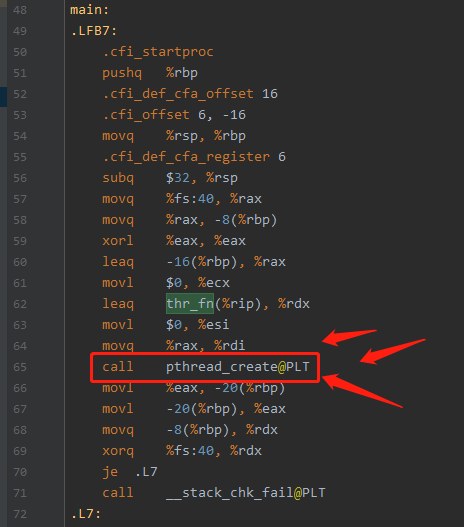
从上图可以看出, 汇编代码 使用了 call 指令来调用 操作系统的 pthread_create 函数,后面的 @PLT 是 Process Link Table 过程链接表 的缩写。
首先声明一下,指令并行主要有两种技术:
1,Instruction-Level Parallelism 指令级别技术,单核里面设计了多个单元来并行不同的指令,这个技术本文不讲。
指令级别技术 具体的 请看 《计算机体系结构-量化研究方法》第3章,如下图:

2,Thread-Level Parallelism , 线程级别并行技术,主要用于多核。这是本文的重点,也就是 pthread_create 函数底层使用的技术
这个逻辑是这样的,多线程是操作系统封装的东西,如果CPU是单核的,那整体来说,不同的程序都是不断地切换CPU时间片,机器指令并行 只能用 Instruction-Level Parallelism 技术,怎么切换程序,是操作系统干的事情。
在多核情况下,怎么让多条机器指令并行执行,其实也是操作系统干的事情,操作系统提供了多线程的API 接口,告诉程序员,你使用这个 pthread_create 接口,我操作系统会尽量 ,尽量让你不同的线程的机器指令能够在不同的CPU核心上 并行执行。
这里注意,即使是多核的CPU,寄存器的数量也是不变的,例如32位通用寄存器有 8个,EAX ~ EDI,双核CPU只有这么多寄存器,4核CPU也是只有这么多寄存器。
所以机器指令并行,必须是两个指令操作不同的寄存器,它才能并行,要不多个核心抢寄存器,只能不断压栈弹栈。
接下来 就讲解一些 在 汇编里面 不调 操作系统的 线程函数,怎么让 汇编指令 并行?
因为 pthread_create 也是机器码实现的,肯定有相关的机器码指令,让不同的核心执行不同的指令。
下面开始讲解 Thread-Level Parallelism(线程级并行)的相关原理。这方面的技术,我自己也不是特别懂,推荐几个专业的书籍,自行观看。
1,《计算机体系结构-量化研究方法》第5章,讲得比较详细。
2,《英特尔® 64 位和 IA-32 架构开发人员手册:卷 3A》,专门有一章是讲多核的。
反正无论 指令级别并行,还是线程 级别并行,都是操作系统封装好的东西。
在操作系统之上使用 汇编,如果想让 指令并行,充分利用多核,只需要学会 汇编里面如何调 pthread_create 函数就行。
下面就来讲讲 汇编里面如何调 pthread_create 函数
我在网上没找到 怎么样往 寄存器 写数据 ,再 调 pthread_create 函数,不知道 pthread_create 是取了哪些寄存器作为参数。本人只找到一个问题帖子,《调用pthread_create时应将哪些值设置为寄存器》
一般都是在 C语言里面嵌入汇编代码,所以直接用C语言调 pthread_create 函数 就行,如果一定要用手写汇编来调 pthread_create 函数,可以反汇编 C 代码,照着来抄参数。C 语言如何嵌入 汇编代码,请阅读《X86汇编入门-如何在C语言中使用汇编》
扩展知识:
1,windows 系统 的汇编 call 有标准定义,文档链接。
相关阅读:
由于笔者的水平有限, 加之编写的同时还要参与开发工作,文中难免会出现一些错误或者不准确的地方,恳请读者批评指正。如果读者有任何宝贵意见,可以加我微信 Loken1,QQ:2338195090。