

函数传参,主流 有两种技术方式 实现。
1,堆栈传参。
2,寄存器传参。
堆栈传参 的实现比较简单,不容易出错,所以应用比较广泛。寄存器传参 速度快,性能好。
既然 寄存器传参 的方式那么好,高级语言为什么不全部都用 寄存器传参 实现一些功能,开发难度是一个需要考量的因素,不是哪个性能好就用哪个。
即使性能好,写出来的东西一堆bug怎么办。
所以在 JAVA 里面使用的是堆栈传参,而 C/C++ 语言在 参数不多, 寄存器足够的情况下,会优选使用寄存器传参,不够再使用堆栈传参。这也是 C/C++ 比 JAVA 性能好的原因之一。

高级语言中,有些语言也会在某些地方采用 寄存器传参 来代替 堆栈传参,例如 PHP 的 execute_data,opline,如下:

本文 主要从 汇编代码的角度,演示 寄存器传参 跟 堆栈传参 区别。举个例子。
ADD reg/mem,%eax上面的 是 ADD 指令,往 eax 寄存器上加东西,注意这个 source (来源),他可以是 register 寄存器,也可以是 memory 一个内存地址。
# 寄存器传递,把 ebx 的4字节数据加给 eax。
ADD %ebx,%eax
# 注意 (),这个是对地址求值,也就是把 ebp 偏移 8字节的那个块数据的值 加给 eax
ADD 8(%ebp),%eax这个就是 寄存器传参 跟 堆栈传参的 区别。
- 寄存器传参 是调用 ADD 之前 把参数放进去
ebx寄存器里面。 - 堆栈传参 是调用 ADD 之前 把 参数放在
8(%esp)的位置,也就是内存的位置。
ADD 8(%ebp),%eax 这种只是汇编器封装好的写法,底层还是要从内存拿到 CPU,只不过这个过程对使用者来说是透明的。
ADD 8(%ebp),%eax 内存寻址 翻译成 机器指令 占 3个字节,ADD %ebx,%eax 翻译成机器指令 占 2个字节。
所以 ADD 指令 从寄存器拿参数,确实是比从 内存地址拿 参数快。
但为什么 说 寄存器传参会比较复杂,请看下面的代码。
下面是 main 函数调用 一个 add_two 函数的汇编代码,采用寄存器传参。
原始C语言代码:
int add_two(int a,int b){
return a+b;
}
int main() {
int return_num = add_two(1,8);
return return_num - 3;
}寄存器传参代码:
.text
.globl main
.type main, @function
.type add_two, @function
add_two:
movl %ebx, %eax
addl %ecx, %eax
ret
main:
pushl %ebp
movl %esp, %ebp
/* 两个参数 分别传进去 ebx ,ecx,所以需要先 保存 ebx ,ecx 的旧值进去 堆栈。 */
pushl %ebx
pushl %ecx
/* 开始寄存器传参, 参数 1 丢进去 ebx,参数 8 丢进去 ecx */
movl $1, %ebx
movl $8, %ecx
call add_two
/* 从堆栈恢复 ecx ebx的值 */
popl %ecx
popl %ebx
/* 返回值减 3 */
subl $3, %eax
popl %ebp
ret编译命令如下:
gcc -m32 -o main-32 main-32.s上面的代码就是寄存器传参 个 add_two 函数,接下来引用 《汇编语言 基于X86处理器》一书中的一段话。
在过程调用之前,任何存放参数的寄存器须首先入栈,然后向其分配过程参数,在过程返回后再恢复其原始值
这些额外的入栈和出栈操作不仅会让代码混乱,还有可能消除性能优势,而这些优势正是通过使用寄存器参数所期望获得的!此外,程序员还要非常仔细地将 PUSH 与相应的 POP 进行匹配,即使代码存在着多个执行路径。
所以,寄存器传参很复杂,我上面的代码还是简单版的,一个 PUSH 要对应一个 POP,add_two 执行完之后要 顺序把之前压进去的数据弹出来给寄存器。如果还有逻辑分支,PUSH 跟 POP 很容易写错。
add_two 堆栈传参版本的代码如下:
.text
.globl main
.type main, @function
.type add_two, @function
add_two:
pushl %ebp
movl %esp, %ebp
movl 12(%ebp), %eax
addl 8(%ebp), %eax
popl %ebp
ret
main:
pushl %ebp
movl %esp, %ebp
/* 把参数压 进去堆栈 */
pushl $1
pushl $8
call add_two
/* 把之前的两个参数移出堆栈 */
addl $8,%esp
/* 返回值减 3 */
subl $3, %eax
popl %ebp
ret下面通过 gdb 一步一步讲解 堆栈传参是怎么一回事,开始
gcc -m32 -o main-32 main-32.s
# 运行 gdb
gdb ./main-32
# 显示寄存器窗口
layout regs
# 断点
b *main从下图可以看出,在 pushl $1 执行之前,esp 等于 0xffffd348,请看下图:
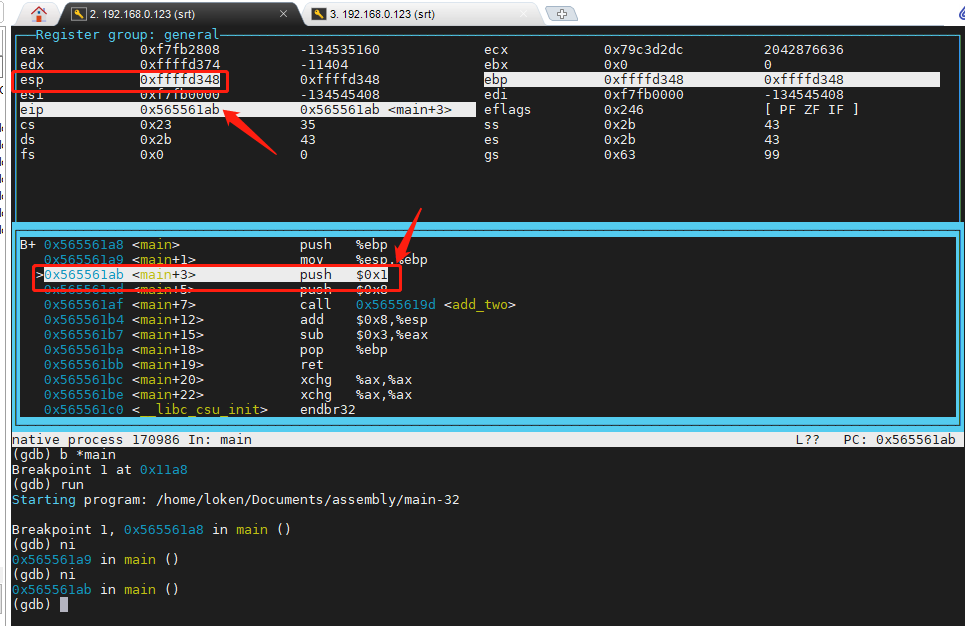
现在 再 敲入命令 ni,执行 pushl $1,如下图所示,esp 变成了 0xffffd344,请看下图:
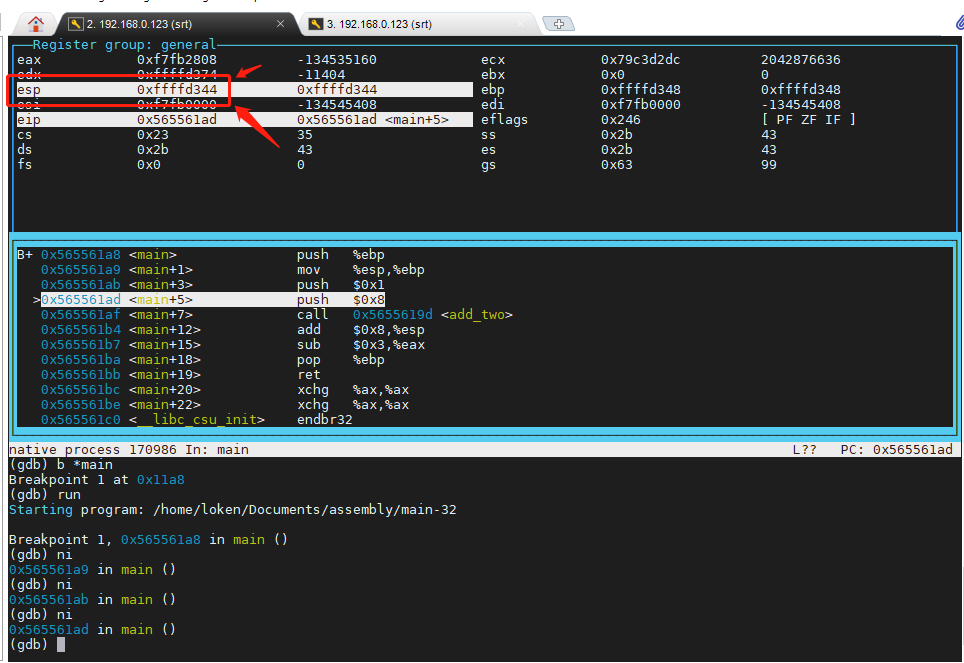
所以,此时,打印 一下 0xffffd344 ~ 0xffffd348 的内存数据,肯定是之前存进去的 1。如下图所示:
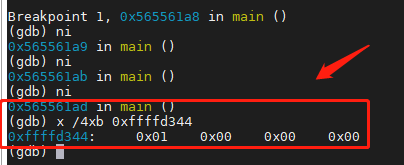
这里注意,我的电脑是 小端 序存储的,所以是倒着来的。
此时,参数 1 已经被放进去内存里面了。参数 8 同理,参数 8 在 0xffffd340 ~ 0xffffd344 。
现在 敲 si 命令,跳进去 add_two 函数的实现,如下图:
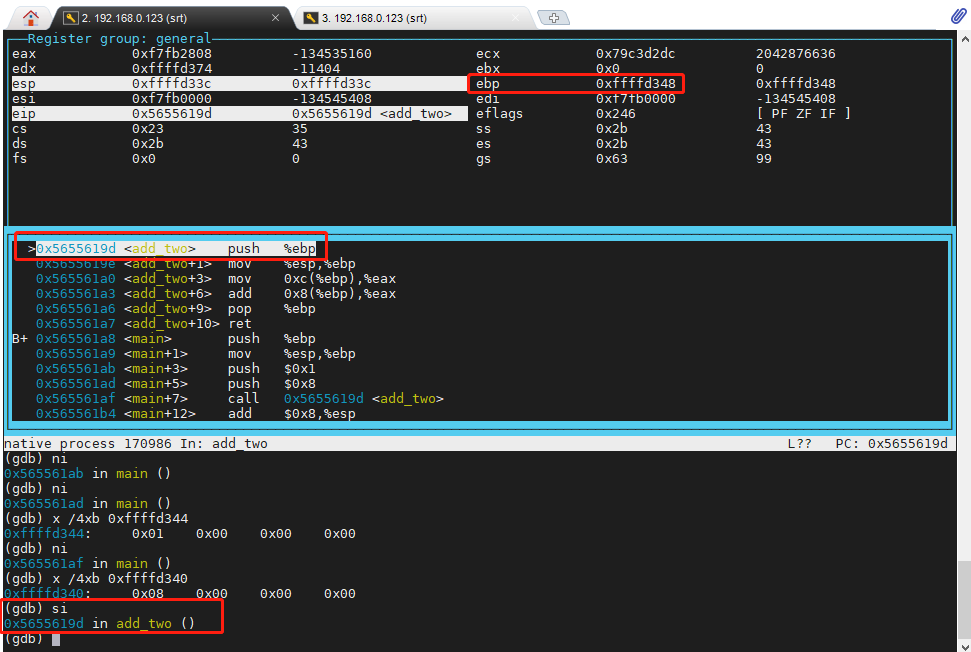
这里要注意,call 指令,会把main 的下一个指令地址存进去堆栈,所以call 会用掉 4 字节的堆栈内存,所以 esp 会减 4,此时 esp 已经从 0xffffd340 减成 0xffffd33c,此时打印一下 0xffffd33c ~ 0xffffd340 的内存,就是 addl $8,%esp 的地址 0x565561b4 ,如下图:

执行完 add_two 就会执行 addl $8,%esp。
此时 add_two 还没开始执行,ebp 现在的值 0xffffd348 是 上层main 函数的值,因为 ebp 是基址,上层函数可能用这个寄存器干了一些事情,所以 add_two 返回去的时候不能改变 main 的 ebp,但是 add_two 又需要 使用 ebp,所以第一句 就是 pushl %ebp 把 main 的 ebp 先存到堆栈内存里,返回去之前再 恢复 ebp。
add_two 的第一句汇编 pushl %ebp 执行完之后,效果图如下:
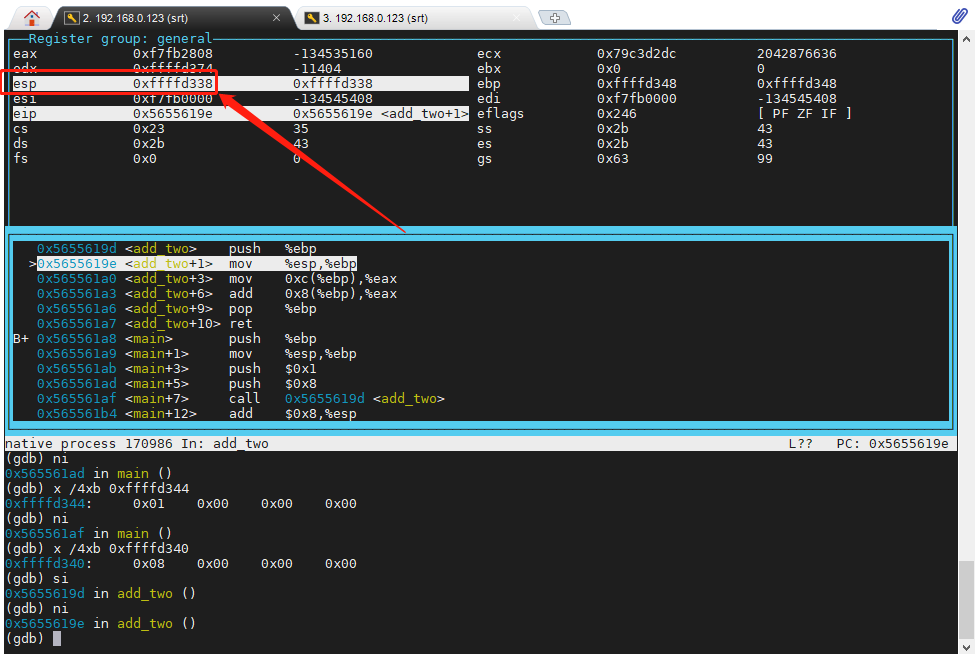
此时,内存里又有 4个 字节被使用掉了,esp 又减了 4,此时 esp 已经从 0xffffd33c 减橙 0xffffd338,此时打印一下 0xffffd338 ~ 0xffffd33c 的内存,就是 main 的 ebp 的值 0xffffd348 ,如下图:

在 敲 ni,执行 movl %esp, %ebp,把 esp 的值 拷贝 给 ebp,方便操作。这里注意 esp 可以定位到之前的 1 跟 8那个参数。
此时此刻,esp 等于 0xffffd338 ,之前 的参数1 在 0xffffd344 ~ 0xffffd348 ,参数 8 在 0xffffd340 ~ 0xffffd344。
所以 参数 8 就等于 esp + 8 字节,为什么是 加 8 字节,因为 call add_two 压了 4字节进去堆栈,pushl %ebp 为了保存 main 的 ebp 又压了 4字节,所以一共 8个字节。
参数 1 就等于 esp + 12字节,这个原理也就是 下面两句代码的由来。
movl 12(%ebp), %eax
addl 8(%ebp), %eax上面这两句 汇编执行完之后,eax 已经有了想要的值 9,最后执行 popl %ebp 恢复 main 的 ebp, 下图是 add_two 中 popl %ebp 执行完后的状态,ebp 已经恢复到 进入 add_two 之前的值了,也就是 0xffffd348。
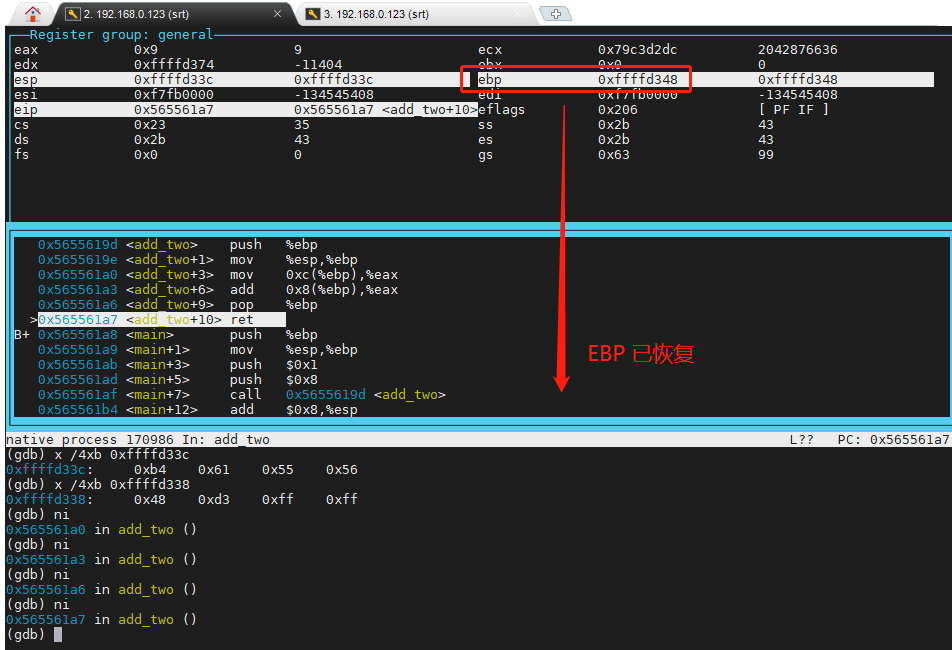
现在 add_two 还有最后一个指令没执行,也就是 ret。
之前说过, add_two 执行完之后,需要把 eip 寄存器改到 main 执行完 add_two 的下一行汇编代码的地址。下一行汇编代码的地址已经在 call add_two 的时候,压进去堆栈了,就是 0xffffd33c ~ 0xffffd340。此刻 esp 正好也是 0xffffd33c ,所以 ret 直接在 esp 的位置取 4个字节 丢进去 eip 就行了。
那 4 个字节 0xffffd33c ~ 0xffffd340 就是 addl $8,%esp ,也就是下一行汇编代码。
敲 ni,让程序 执行完 add_two 的 ret 指令,效果图如下,此刻代码已经回到 main addl $8,%esp 的位置的了 。
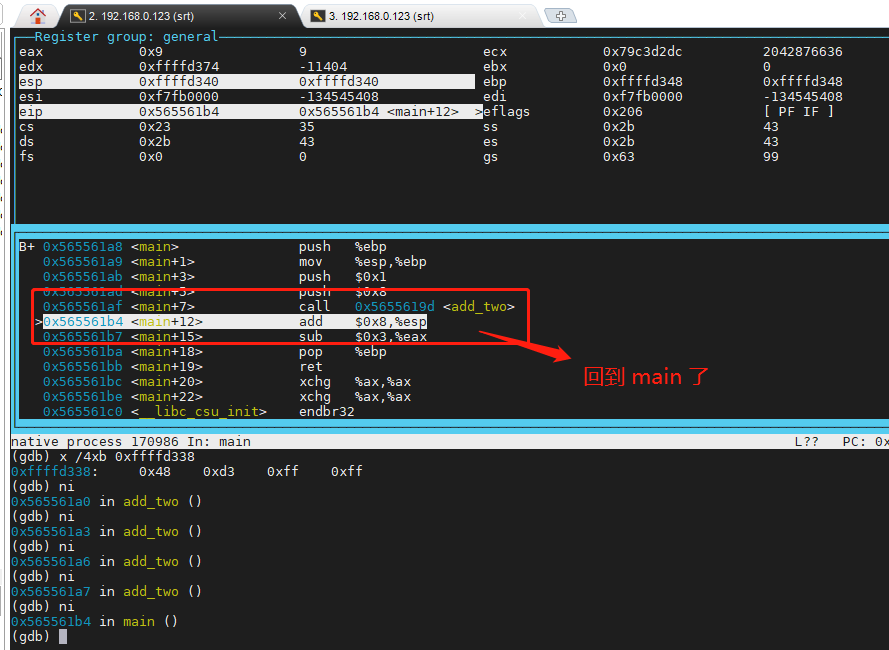
现在,此时此刻,堆栈还有两个东西没有处理,就是之前压进去的 参数1 参数 8,在本文代码里不处理这两个东西也可以,因为本文没有嵌套使用 main 函数,但是正规的做法是需要把 这两个参数剔除出 堆栈,怎么剔除?两个参数一共占 8字节,直接把 esp 加 8就行了。
最后 就是 把 add_two 返回的参数,减去 3 。
代码运行完毕。
从上面的流程看,堆栈传参 确实比较方便,只需要记录一下压了多少字节参数进堆栈,出来的之后 esp 加上多少字节就可以了。
寄存器传参 以及 堆栈传参,还有一些更简洁,不容易出错的写法跟指令,在 《X86 汇编语言,基于x86》第 8 章。
相关阅读:
强烈推荐阅读 《X86 汇编语言,基于x86》第 8 章,讲解得更加详细。
- 《X86 汇编语言,基于x86》第 8 章
- 《汇编中的堆栈传参》
由于笔者的水平有限, 加之编写的同时还要参与开发工作,文中难免会出现一些错误或者不准确的地方,恳请读者批评指正。如果读者有任何宝贵意见,可以加我微信 Loken1。QQ:2338195090。