

如果程序运行在 32位 模式下,常用的寄存器(register)有以下8个。
- EAX,EAX 是 累加器 (accumulator), 它是很多加法乘法指令的缺省寄存器。
- EBX,EBX 是 基地址(base)寄存器, 在内存寻址时存放基地址。
- ECX,ECX 是 计数器(counter), 是重复(REP)前缀指令和LOOP指令的内定计数器。
- EDX,EDX 总是被用来放整数除法产生的余数。
- EBP,EBP是 基址指针(BASE POINTER), 软件破解领域 经常用到这个 基址
- ESP ,ESP 是 堆栈指针(stack point)
- ESI/EDI,分别叫做 源/目标索引寄存器(source/destination index),因为在很多字符串操作指令中,
DS:ESI指向源串,而ES:EDI指向目标串。这句话我也不明白
一共有 8 个 通用 寄存器,什么是通用? 就是 EAX 寄存器可以干 EBX 寄存器的活。他们其实都是同一种寄存器,CPU 提供的寄存器,只是从使用习惯上 EAX 叫 EAX。乘法指令 能不能用 EBX 寄存器?也是可以的,只是使用习惯上没这么搞。
本文主要讲解 EAX 寄存器的使用。上面说了 乘法指令 默认使用 EAX,咱们现在就用代码实际演示一次 乘法指令怎么默认使用 EAX。
汇编代码如下:
.file "main.c"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr32
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
subl $16, %esp
call __x86.get_pc_thunk.ax
addl $_GLOBAL_OFFSET_TABLE_, %eax
movl $1, -4(%ebp)
addl $1, -4(%ebp)
movl $0, %eax
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE0:
.size main, .-main
.section .text.__x86.get_pc_thunk.ax,"axG",@progbits,__x86.get_pc_thunk.ax,comdat
.globl __x86.get_pc_thunk.ax
.hidden __x86.get_pc_thunk.ax
.type __x86.get_pc_thunk.ax, @function
__x86.get_pc_thunk.ax:
.LFB1:
.cfi_startproc
movl (%esp), %eax
ret
.cfi_endproc
.LFE1:
.ident "GCC: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 4
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 4
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 4
4:
先用 gdb 简单调试一下上面这段汇编代码,不熟悉 gdb 的可以先看以下教程。
上面的代码,是 32 位的汇编,在 64位 的 ubuntu下要 加上 -m32 才能编译成可执行文件。
gcc -m32 -o main32 main-32.s再执行以下命令进入 gdb 调试
# 运行 gdb
gdb ./main32
# 显示寄存器窗口
layout regs
# 自动反汇编后面要执行的代码
set disassemble-next-line on
# 设置 main 断点
b main
# 查看汇编代码
disassemble
# 查看寄存器的值
i registers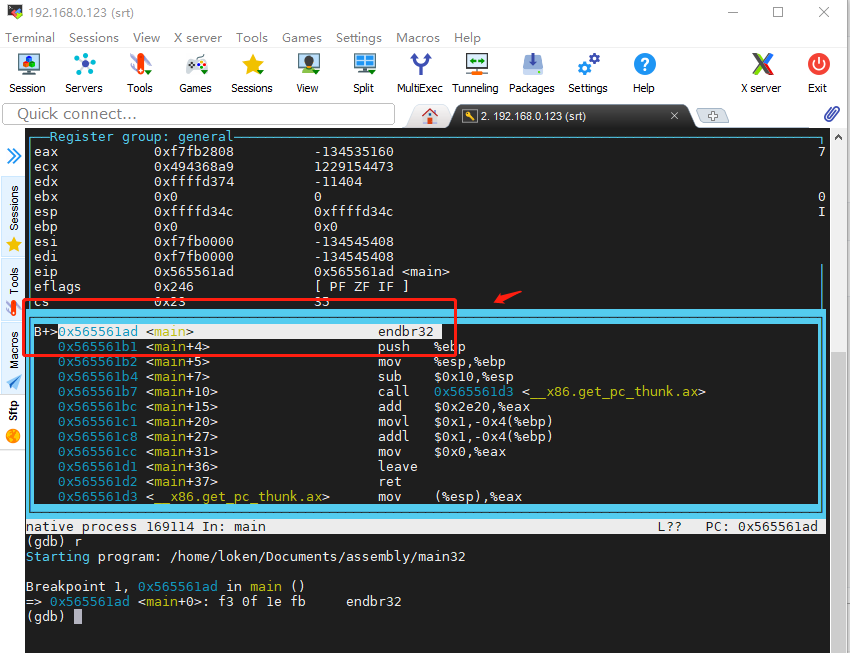
GDB 调试 C语言 用的是 s(step) 跟 n(next),单步调试汇编是 si 跟 ni 。
GDB 调试技巧讲完了。下面开始一行一行代码讲解。
不熟悉 AT&T 汇编语法的可以先快速看一遍 官方文档 《Using as-The GNU Assembler》
相应的 X86 指令可以看 《英特尔® 64 位和 IA-32 架构开发人员手册》。
下面开始一行一行代码讲解。
.file "main.c"
.text
.globl main
.type main, @function1,.file 在官网的手册 的注释是 tells as that we are about to start a new logical file. string is the new file name.
我个人猜测,这应该是告诉 gdb 往哪个文件做debug,调试用的。
2,.text,Tells as to assemble the following statements onto the end of the text subsection numbered subsection, which is an absolute expression. If subsection is omitted, subsection number zero is used.(官网注释,我也不懂)
3,.globl,应该是告诉 链接器 ld 一些信息。
4,.type,我也不会,自己看文档。
上面的 汇编代码,.file,.text,.globl 等这些,其实是伪指令(Assembler Directives)。
伪指令 是汇编器 搞出来的东西,不是CPU指令集提供的,你可以理解为 伪指令 是基于 CPU指令集 封装的。
不伪的指令就是 CPU 指令集,pushl %rbp 这种就是真正的指令。
实际上,伪指令 跟 真正的指令,你用汇编的时候,是没有感知的。只是内部实现有区别,所以把这两个东西看成一个东西就行。
main:
.LFB0:
.cfi_startproc
endbr32
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -81,main: 这行代码,是一个 label ,把它理解成 C语言的 goto 的标记就行。
2,.LFB0: 也是一个 goto 标记。在汇编里面 是 jmp 指令
3,.cfi_startproc,这是 cfi 指令,调试用的。
4,endbr32, endbr instructions at the start of generated functions to make IBT (indirect branch tracking) work。还是生成调试信息用的。
5,pushl %ebp,把 ebp 寄存器的值 压进去 esp 寄存器,不用写上 esp,push 指令默认就是存到 esp 的。
这个 push 指令非常重要,详解讲一下。后面的 l 是 long 的缩写,代表 4 字节。因为这是 32 位的汇编代码。 64位是 pushq。
为什么 第一句 指令是 pushl %ebp ?
这是因为 把 main 函数的入口作为一个基址方便后续操作。一般 push 指令 对应一个 pop,或者类似 pop 的功能指令。在本文里面是 leave 指令,leave 指令会把之前压在 esp 的堆栈数据全部弹出来。
这里要 写一下 push 跟 pop 的汇编代码。
6,.cfi_def_cfa_offset 8 ,cfi 指令,看这篇文章 《gas-explanation-of-cfi-def-cfa-offset》
cfa 其实就是永远指向 esp 的头部,调试指令,自己写汇编一般用不到。
7,.cfi_offset 5, -8,
movl %esp, %ebp
.cfi_def_cfa_register 5
subl $16, %esp
call __x86.get_pc_thunk.ax
addl $_GLOBAL_OFFSET_TABLE_, %eax
movl $1, -4(%ebp)
addl $1, -4(%ebp)
movl $0, %eax
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc1,movl %esp, %ebp 把 esp 寄存器的值 拷贝给 ebp,注意看 gdb 的 寄存器窗口,ebp 变白色了。还有一个重点 eip 寄存器永远是下一条要执行的指令的地址。这里还有一个重点,AT&T 的 源和目标的顺序和 Intel 相反,在 intel 里面是 mov ebp,esp。
2,subl $16, %esp,把 esp 寄存器的值减 16,AT&T 的语法 前面要加 $。
3,call __x86.get_pc_thunk.ax,调用一个函数,GOT表。阅读 这篇文章 《__x86.get_pc_thunk.ax函数》
4,movl $1, -4(%ebp),addl $1, -4(%ebp),用 GOT 表来操作变量,不太容易看懂。
5,leave,退出
/lib32/libc.so 上面的汇编程序是在这个运行时库里面跑的。
TODO:
现在应用层的汇编优化,通常都是在 64 位下面做的。 32 位本来就没有64位 快,用汇编也只是处理一些 gcc 编译优化没有顾及到的地方,想让程序更快。
而且现在大部分机器都是 64 位,做汇编优化是需要研发成本的,通常不会 为了一个 32 位的程序去使用汇编。
所以本书,只是提及一下 32 位的汇编一点点知识,后续的汇编代码都是基于 64位的。
相关阅读:
- EAX、ECX、EDX、EBX寄存器的作用
- 《Using as-The GNU Assembler》
- 《英特尔® 64 位和 IA-32 架构开发人员手册:卷 1》
- 《英特尔® 64 位和 IA-32 架构开发人员手册:卷 2A》
由于笔者的水平有限, 加之编写的同时还要参与开发工作,文中难免会出现一些错误或者不准确的地方,恳请读者批评指正。如果读者有任何宝贵意见,可以加我微信 Loken1。QQ:2338195090。